The post DBpedia Day in Leipzig @ SEMANTiCS 2023 appeared first on DBpedia Association.
]]>First and foremost, we would like to thank the Institute for Applied Informatics for supporting our community and many thanks to the SEMANTiCS organization team for hosting this year’s community meeting.
Opening of the DBpedia Day

Also this year, our CEO Sebastian Hellmann opened the community meeting by presenting the Databus 2.1.0 project (slides). Afterwards, Edward Curry from the University of Galway gave his fantastic keynote presentation “Towards Foundation Models for Data Spaces”. You can read his abstract here.
Member Presentation Session

Milan Dojchinovski, InfAI/DBpedia Association and CTU Prague, started the member presentation session with a short welcome. The first speaker was Angel Moreno, GNOSS, with his presentation “NEURALIA Rioja: the unified Knowledge Graph of La Rioja Government which integrates twenty six sources of information in a single access point” (slides). Shortly after, Enno Meijers, KB, talked about “Network-of-Terms, bringing links to your data” (slides). Next, Sarah Binta Alam Shoilee, Network Institute & Vrije Universiteit Amsterdam talked about ”Cultural AI Lab”(slides). This was followed by the presentation “Linking and Consumption of DBpedia in TriplyDB” by Kathrin Dentler & Wouter Beek, TriplyDB (slides). Then Sebastian Gabler, SWC, talked about “Using Dewey Decimal Classification for linked data” (slides). Finally, the last talk of this session was given by Sebastian Tramp, eccenca, with “Using DBpedia Services with eccenca Corporate Memory and eccenca.my”.
For further details of the presentations follow the links to the slides.
- “NEURALIA Rioja: the unified Knowledge Graph of La Rioja Government which integrates twenty six sources of information in a single access point” by Angel Moreno, GNOSS (slides)
- “Network-of-Terms, bringing links to your data” by Enno Meijers, KB (slides)
- ”Cultural AI Lab” by Sarah Binta Alam Shoilee, Network Institute & Vrije Universiteit Amsterdam (slides)
- “Linking and Consumption of DBpedia in TriplyDB” by Kathrin Dentler & Wouter Beek, TriplyDB (slides)
- “Using Dewey Decimal Classification for linked data” by Sebastian Gabler, SWC (slides)
- “Using DBpedia Services with eccenca Corporate Memory and eccenca.my” by Sebastian Tramp, eccenca (slides)
DBpedia Science: Linking and Consumption

This session was dedicated to the most recent research on linking and consumption of the DBpedia Knowledge Graph and beyond. Novel methods, tools and challenges around linking and consumption of knowledge graphs were presented and discussed. Milan Dojchinovski, InfAI/DBpedia Association and CTU Prague, chaired this session with five talks. Hereafter you will find the presentations given during this session:
- “Open Research Knowledge Graph” by Sören Auer, TIB
- “Blocking Methods for Entity Resolution on Knowledge Graphs” by Daniel Obraczka, Data Science Center ScaDS.AI Dresden/Leipzig (slides)
- “Validating SHACL Constraints with Reasoning: Lessons Learned from DBpedia” by Maribel Acosta, TUM School of Computation, Information and Technology
- “Exploiting Semi-Structured Information in Wikipedia for Knowledge Graph Construction” by Nicolas Heist, Data and Web Science Group, University of Mannheim (slides)
- “Using Pre-trained Language Models for Abstractive DBpedia Summarization” by Hamada Zahera, Data Science Group, Paderborn University (slides)
DBpedia Community session
Sebastian Hellmann, InfAI/DBpedia Association, hosted this year’s community session. DBpedia has had a major impact on data landscape during our 15-year journey. This session discussed the progress of the vision of a “Global and Unified Access to Knowledge Graphs”, which paved the way for an international FAIR Open Data Space driven by knowledge graphs. The session focused on the potential of large-scale knowledge graphs to reshape the open data domain. Topics included how the DBpedia community can pool its data, tools and know-how more effectively, and how we can make these assets more findable, accessible and interoperable. The session provided an insightful discourse on the future of open data and how we can forge strategic alliances across diverse industrial sectors.
Following, you find the presentations of this session:
- “Update Japanese DBpedia” Hideaki Takeda, LODI (slides)
- Several impulses about different topics and follow-up discussion, moderated by Sebastian Hellmann, InfAI/DBpedia Association (discussion document)
In case you missed the event, all slides are also available on our event page. Further insights, feedback and photos about the event are available on Twitter via #DBpediaDay.
We are now looking forward to more DBpedia events in the upcoming months and at next year’s SEMANTiCS Conference, which will be held in Amsterdam, Netherlands.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Maria & Julia
on behalf of the DBpedia Association
The post DBpedia Day in Leipzig @ SEMANTiCS 2023 appeared first on DBpedia Association.
]]>The post DBpedia Snapshot 2022-09 Release appeared first on DBpedia Association.
]]>News since DBpedia Snapshot 2022-03
- New Abstract Extractor due to GSOC 2022 (credits to Celian Ringwald)
- Work in progress: Smoothing the community issue reporting and fixing at Github
What is the “DBpedia Snapshot” Release?
Historically, this release has been associated with many names: “DBpedia Core”, “EN DBpedia”, and — most confusingly — just “DBpedia”. In fact, it is a combination of —
- EN Wikipedia data — A small, but very useful, subset (~ 1 Billion triples or 14%) of the whole DBpedia extraction using the DBpedia Information Extraction Framework (DIEF), comprising structured information extracted from the English Wikipedia plus some enrichments from other Wikipedia language editions, notably multilingual abstracts in ar, ca, cs, de, el, eo, es, eu, fr, ga, id, it, ja, ko, nl, pl, pt, sv, uk, ru, zh.
- Links — 62 million community-contributed cross-references and owl:sameAs links to other linked data sets on the Linked Open Data (LOD) Cloud that allow to effectively find and retrieve further information from the largest, decentral, change-sensitive knowledge graph on earth that has formed around DBpedia since 2007.
- Community extensions — Community-contributed extensions such as additional ontologies and taxonomies.
Release Frequency & Schedule
Going forward, releases will be scheduled for the 1th of February, May, August, and November (with +/- 5 days tolerance), and are named using the same date convention as the Wikipedia Dumps that served as the basis for the release. An example of the release timeline is shown below:
| September 6–8 | September 8–20 | September 20–November 1 | November 1 –November 15 |
| Wikipedia dumps for June 1 become available on https://dumps.wikimedia.org/ | Download and extraction with DIEF | Post-processing and quality-control period | Linked Data and SPARQL endpoint deployment |
Data Freshness
Given the timeline above, the EN Wikipedia data of DBpedia Snapshot has a lag of 1-4 months. We recommend the following strategies to mitigate this:
- DBpedia Snapshot as a kernel for Linked Data: Following the Linked Data paradigm, we recommend using the Linked Data links to other knowledge graphs to retrieve high-quality and recent information. DBpedia’s network consists of the best knowledge engineers in the world, working together, using linked data principles to build a high-quality, open, decentralized knowledge graph network around DBpedia. Freshness and change-sensitivity are two of the greatest data-related challenges of our time, and can only be overcome by linking data across data sources. The “Big Data” approach of copying data into a central warehouse is inevitably challenged by issues such as co-evolution and scalability.
- DBpedia Live: Wikipedia is unmistakenly the richest, most recent body of human knowledge and source of news in the world. DBpedia Live is just minutes behind edits on Wikipedia, which means that as soon as any of the 120k Wikipedia editors press the “save” button, DBpedia Live will extract fresh data and update. DBpedia Live is currently in tech preview status and we are working towards a high-available and reliable business API with support. DBpedia Live consists of the DBpedia Live Sync API (for syncing into any kind of on-site databases), Linked Data and SPARQL endpoint.
- Latest-Core is a dynamically updating Databus Collection. Our automated extraction robot “MARVIN” publishes monthly dev versions of the full extraction, which are then refined and enriched to become Snapshot.
Data Quality & Richness
We would like to acknowledge the excellent work of Wikipedia editors (~46k active editors for EN Wikipedia), who are ultimately responsible for collecting information in Wikipedia’s infoboxes, which are refined by DBpedia’s extraction into our knowledge graphs. Wikipedia’s infoboxes are steadily growing each month and according to our measurements grow by 150% every three years. EN Wikipedia’s inboxes even doubled in this timeframe. This richness of knowledge drives the DBpedia Snapshot knowledge graph and is further potentiated by synergies with linked data cross-references. Statistics are given below.
Data Access & Interaction Options
Linked Data
Linked Data is a principled approach to publishing RDF data on the Web that enables interlinking data between different data sources, courtesy of the built-in power of Hyperlinks as unique Entity Identifiers.
HTML pages comprising Hyperlinks that confirm to Linked Data Principles is one of the methods of interacting with data provided by the DBpedia Snapshot, be it manually via the web browser or programmatically using REST interaction patterns via https://dbpedia.org/resource/{entity-label} pattern. Naturally, we encourage Linked Data interactions, while also expecting user-agents to honor the cache-control HTTP response header for massive crawl operations. Instructions for accessing Linked Data, available in 10 formats.
SPARQL Endpoint
This service enables some astonishing queries against Knowledge Graphs derived from Wikipedia content. The Query Services Endpoint that makes this possible is identified by http://dbpedia.org/sparql, and it currently handles 7.2 million queries daily on average. See powerful queries and instructions (incl. rates and limitations).
An effective Usage Pattern is to filter a relevant subset of entity descriptions for your use case via SPARQL and then combine with the power of Linked Data by looking up (or de-referencing) data via owl:sameAs property links en route to retrieving specific and recent data from across other Knowledge Graphs across the massive Linked Open Data Cloud.
Additionally, DBpedia Snapshot dumps and additional data from the complete collection of datasets derived from Wikipedia are provided by the DBpedia Databus for use in your own SPARQL-accessible Knowledge Graphs.
DBpedia Ontology
This Snapshot Release was built with DBpedia Ontology (DBO) version: https://databus.dbpedia.org/ontologies/dbpedia.org/ontology–DEV/2021.11.08-124002 We thank all DBpedians for the contribution to the ontology and the mappings. See documentation and visualizations, class tree and properties, wiki.
DBpedia Snapshot Statistics
Overview. Overall the current Snapshot Release contains more than 850 million facts (triples).
At its core, the DBpedia ontology is the heart of DBpedia. Our community is continuously contributing to the DBpedia ontology schema and the DBpedia infobox-to-ontology mappings by actively using the DBpedia Mappings Wiki.
The current Snapshot Release utilizes a total of 55 thousand properties, whereas 1377 of these are defined by the DBpedia ontology.
Classes. Knowledge in Wikipedia is constantly growing at a rapid pace. We use the DBpedia Ontology Classes to measure the growth: Total number in this release (in brackets we give: a) growth to the previous release, which can be negative temporarily and b) growth compared to Snapshot 2016-10):
- Persons: 1833500 (1.02%, 1.15%)
- Places: 757436 (1.01%, 1842.91%), including but not limited to 597548 (1.01%, 5584.56%) populated places
- Works 619280 (1.01%, 628.71%), including, but not limited to
- 158895 (1.01%, 1.40%) music albums
- 147192 (1.02%, 16.25%) films
- 25182 (1.01%, 12.71%) video games
- Organizations: 350329 (1.01%, 110.83%), including but not limited to
- 88722 (1.01%, 2.28%) companies
- 64094 (0.99%, 64094.00%) educational institutions
- Species: 1955775 (1.01%, 325962.50%)
- Plants: 4977 (0.64%, 1.10%)
- Diseases: 10837 (1.02%, 8.74%)
Detailed Growth of Classes: The image below shows the detailed growth for one class. Click on the links for other classes: Place, PopulatedPlace, Work, Album, Film, VideoGame, Organisation, Company, EducationalInstitution, Species, Plant, Disease. For further classes adapt the query by replacing the <http://dbpedia.org/ontology/CLASS> URI. Note, that 2018 was a development phase with some failed extractions. The stats were generated with the Databus VOID Mod.
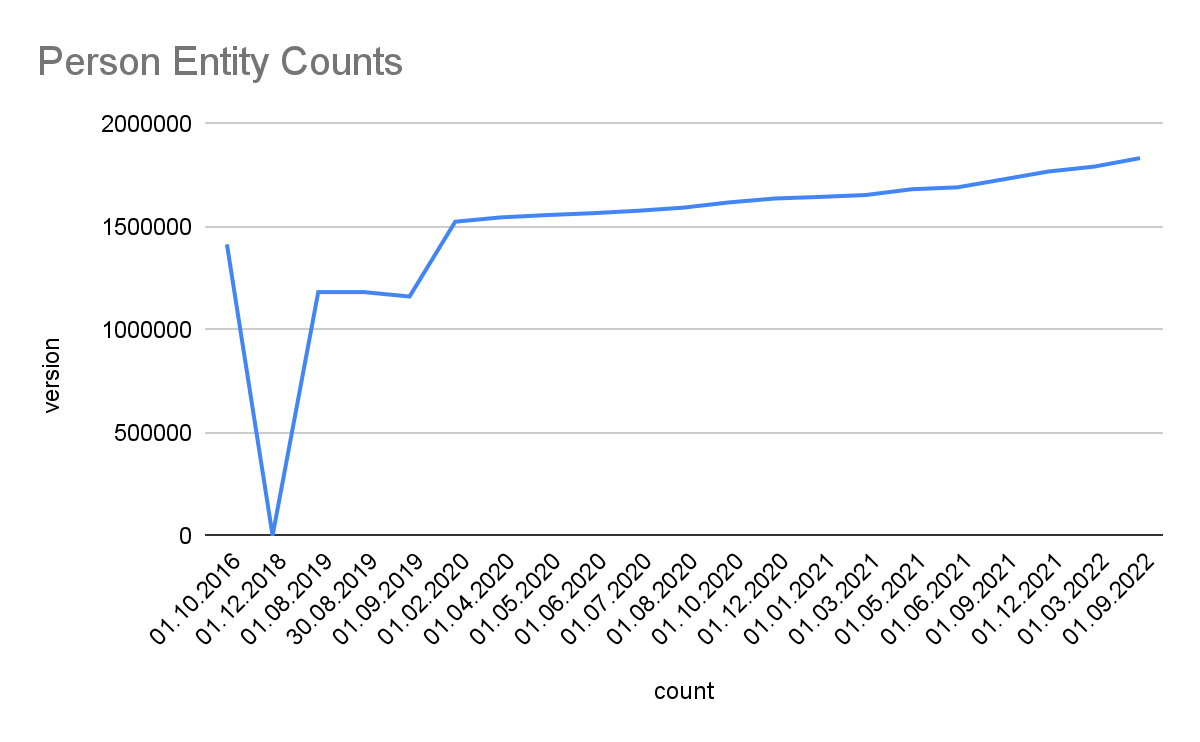
Links. Linked Data cross-references between decentral datasets are the foundation and access point to the Linked Data Web. The latest Snapshot Release provides over 130.6 million links from 7.62 million entities to 179 external sources.
Top 11
###TOP11###
33,860,047 http://www.wikidata.org
7,147,970 https://global.dbpedia.org
4,308,772 http://yago-knowledge.org
3,832,100 http://de.dbpedia.org
3,704,534 http://fr.dbpedia.org
2,971,751 http://viaf.org
2,912,859 http://it.dbpedia.org
2,903,130 http://es.dbpedia.org
2,754,466 http://fa.dbpedia.org
2,571,787 http://sr.dbpedia.org
2,563,793 http://ru.dbpedia.org
Top 10 without DBpedia namespaces
###TOP10###
33,860,047 http://www.wikidata.org
4,308,772 http://yago-knowledge.org
2,971,751 http://viaf.org
1,687,386 http://d-nb.info
609,604 http://sws.geonames.org
596,134 http://umbel.org
533,320 http://data.bibliotheken.nl
430,839 http://www.w3.org
417,034 http://musicbrainz.org
104,433 http://linkedgeodata.org
DBpedia Extraction Dumps on the Databus
All extracted files are reachable via the DBpedia account on the Databus. The Databus has two main structures:
- In groups, artifacts, version, similar to software in Maven: https://databus.dbpedia.org/$user/$group/$artifact/$version/$filename
- In Databus collections that are SPARQL queries over https://databus.dbpedia.org/yasui filtering and selecting files from these artifacts.
Snapshot Download. For downloading DBpedia Snapshot, we prepared this collection, which also includes detailed releases notes: https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2022-03
The collection is roughly equivalent to http://downloads.dbpedia.org/2016-10/core/
Collections can be downloaded in many different ways, some download modalities such as bash script, SPARQL, and plain URL list are found in the tabs at the collection. Files are provided as bzip2 compressed n-triples files. In case you need a different format or compression, you can also use the “Download-As” function of the Databus Client (GitHub), e.g. -s $collection -c gzip would download the collection and convert it to GZIP during download.
Replicating DBpedia Snapshot on your server can be done via Docker, see https://hub.docker.com/r/dbpedia/virtuoso-sparql-endpoint-quickstart
git clone https://github.com/dbpedia/virtuoso-sparql-endpoint-quickstart.git
cd virtuoso-sparql-endpoint-quickstart
COLLECTION_URI=https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2022-09
VIRTUOSO_ADMIN_PASSWD=password docker-compose up
Download files from the whole DBpedia extraction. The whole extraction consists of approx. 20 Billion triples and 5000 files created from 140 languages of Wikipedia, Commons and Wikidata. They can be found in https://databus.dbpedia.org/dbpedia/(generic|mappings|text|wikidata)
You can copy-edit a collection and create your own customized (e.g.) collections via “Actions” -> “Copy Edit” , e.g. you can Copy Edit the snapshot collection above, remove some files that you do not need and add files from other languages. Please see the Rhizomer use case: Best way to download specific parts of DBpedia. Of course, this only refers to the archived dumps on the Databus for users who want to bulk download and deploy into their own infrastructure. Linked Data and SPARQL allow for filtering the content using a small data pattern.
Acknowledgments
First and foremost, we would like to thank our open community of knowledge engineers for finding & fixing bugs and for supporting us by writing data tests. We would also like to acknowledge the DBpedia Association members for constantly innovating the areas of knowledge graphs and linked data and pushing the DBpedia initiative with their know-how and advice. OpenLink Software supports DBpedia by hosting SPARQL and Linked Data; University Mannheim, the German National Library of Science and Technology (TIB) and the Computer Center of University Leipzig provide persistent backups and servers for extracting data. We thank Marvin Hofer and Mykola Medynskyi for technical preparation. This work was partially supported by grants from the Federal Ministry for Economic Affairs and Energy of Germany (BMWi) for the LOD-GEOSS Project (03EI1005E), as well as for the PLASS Project (01MD19003D).
The post DBpedia Snapshot 2022-09 Release appeared first on DBpedia Association.
]]>The post DBpedia Snapshot 2022-06 Release appeared first on DBpedia Association.
]]>You can still use the last Snapshot Release of version 2022-03.
We want to address the current problem and future solutions in the following.
We encountered several new issues, but the major problem is that the current version of DBpedias Abstract Extractor is no longer working. Wikimedia/Wikipedia seems to have increased the requests per second restrictions on their old API.
- Current API https://en.wikipedia.org/w/api.php
As a result, we could not extract any version of English abstracts for April, May, or June 2022 (not even thinking about the other 138 languages). We decided not to publish a mixed version with overlapping core data that is older than three months (e.g., abstracts and mapping-based data).
For a solution, a GSOC project was already promoted in early 2022 that specifies the task of improving abstract extraction. The project was accepted and is currently running. We tested several new promising strategies to implement a new Abstract Extractor.
- New API https://en.wikipedia.org/api/rest_v1/
- local deployment of Mediawiki for Wikitext-template parsing
We will give further status updates on this project in the future.
The announcement of the next Snapshot Release (2022-09) is scheduled for November the 1st.
The post DBpedia Snapshot 2022-06 Release appeared first on DBpedia Association.
]]>The post DBpedia Snapshot 2022-03 Release appeared first on DBpedia Association.
]]>News since DBpedia Snapshot 2021-12
- Release notes are now maintained in the Databus Collection (2022-03)
- Image and Abstract Extractor was improved
- Work in progress: Smoothing the community issue reporting and fixing at Github
What is the “DBpedia Snapshot” Release?
Historically, this release has been associated with many names: “DBpedia Core”, “EN DBpedia”, and — most confusingly — just “DBpedia”. In fact, it is a combination of —
- EN Wikipedia data — A small, but very useful, subset (~ 1 Billion triples or 14%) of the whole DBpedia extraction using the DBpedia Information Extraction Framework (DIEF), comprising structured information extracted from the English Wikipedia plus some enrichments from other Wikipedia language editions, notably multilingual abstracts in ar, ca, cs, de, el, eo, es, eu, fr, ga, id, it, ja, ko, nl, pl, pt, sv, uk, ru, zh.
- Links — 62 million community-contributed cross-references and owl:sameAs links to other linked data sets on the Linked Open Data (LOD) Cloud that allow to effectively find and retrieve further information from the largest, decentral, change-sensitive knowledge graph on earth that has formed around DBpedia since 2007.
- Community extensions — Community-contributed extensions such as additional ontologies and taxonomies.
Release Frequency & Schedule
Going forward, releases will be scheduled for the 15th of February, May, July, and October (with +/- 5 days tolerance), and are named using the same date convention as the Wikipedia Dumps that served as the basis for the release. An example of the release timeline is shown below:
| March 6–8 | March 8–20 | March 20–April 15 | April 15–May 1 |
| Wikipedia dumps for June 1 become available on https://dumps.wikimedia.org/ | Download and extraction with DIEF | Post-processing and quality-control period | Linked Data and SPARQL endpoint deployment |
Data Freshness
Given the timeline above, the EN Wikipedia data of DBpedia Snapshot has a lag of 1-4 months. We recommend the following strategies to mitigate this:
- DBpedia Snapshot as a kernel for Linked Data: Following the Linked Data paradigm, we recommend using the Linked Data links to other knowledge graphs to retrieve high-quality and recent information. DBpedia’s network consists of the best knowledge engineers in the world, working together, using linked data principles to build a high-quality, open, decentralized knowledge graph network around DBpedia. Freshness and change-sensitivity are two of the greatest data-related challenges of our time, and can only be overcome by linking data across data sources. The “Big Data” approach of copying data into a central warehouse is inevitably challenged by issues such as co-evolution and scalability.
- DBpedia Live: Wikipedia is unmistakenly the richest, most recent body of human knowledge and source of news in the world. DBpedia Live is just minutes behind edits on Wikipedia, which means that as soon as any of the 120k Wikipedia editors press the “save” button, DBpedia Live will extract fresh data and update. DBpedia Live is currently in tech preview status and we are working towards a high-available and reliable business API with support. DBpedia Live consists of the DBpedia Live Sync API (for syncing into any kind of on-site databases), Linked Data and SPARQL endpoint.
- Latest-Core is a dynamically updating Databus Collection. Our automated extraction robot “MARVIN” publishes monthly dev versions of the full extraction, which are then refined and enriched to become Snapshot.
Data Quality & Richness
We would like to acknowledge the excellent work of Wikipedia editors (~46k active editors for EN Wikipedia), who are ultimately responsible for collecting information in Wikipedia’s infoboxes, which are refined by DBpedia’s extraction into our knowledge graphs. Wikipedia’s infoboxes are steadily growing each month and according to our measurements grow by 150% every three years. EN Wikipedia’s inboxes even doubled in this time frame. This richness of knowledge drives the DBpedia Snapshot knowledge graph and is further potentiated by synergies with linked data cross-references. Statistics are given below.
Data Access & Interaction Options
Linked Data
Linked Data is a principled approach to publishing RDF data on the Web that enables interlinking data between different data sources, courtesy of the built-in power of Hyperlinks as unique Entity Identifiers.
HTML pages comprising Hyperlinks that confirm to Linked Data Principles is one of the methods of interacting with data provided by the DBpedia Snapshot, be it manually via the web browser or programmatically using REST interaction patterns via https://dbpedia.org/resource/{{entity-label} pattern. Naturally, we encourage Linked Data interactions, while also expecting user-agents to honor the cache-control HTTP response header for massive crawl operations. Instructions for accessing Linked Data, available in 10 formats.
SPARQL Endpoint
This service enables some astonishing queries against Knowledge Graphs derived from Wikipedia content. The Query Services Endpoint that makes this possible is identified by http://dbpedia.org/sparql, and it currently handles 7.2 million queries daily on average. See powerful queries and instructions (incl. rates and limitations).
An effective Usage Pattern is to filter a relevant subset of entity descriptions for your use case via SPARQL and then combine with the power of Linked Data by looking up (or de-referencing) data via owl:sameAs property links en route to retrieving specific and recent data from across other Knowledge Graphs across the massive Linked Open Data Cloud.
Additionally, DBpedia Snapshot dumps and additional data from the complete collection of datasets derived from Wikipedia are provided by the DBpedia Databus for use in your own SPARQL-accessible Knowledge Graphs.
DBpedia Ontology
This Snapshot Release was built with DBpedia Ontology (DBO) version: https://databus.dbpedia.org/ontologies/dbpedia.org/ontology–DEV/2021.11.08-124002 We thank all DBpedians for the contribution to the ontology and the mappings. See documentation and visualizations, class tree and properties, wiki.
DBpedia Snapshot Statistics
Overview. Overall the current Snapshot Release contains more than 850 million facts (triples).
At its core, the DBpedia ontology is the heart of DBpedia. Our community is continuously contributing to the DBpedia ontology schema and the DBpedia infobox-to-ontology mappings by actively using the DBpedia Mappings Wiki.
The current Snapshot Release utilizes a total of 55 thousand properties, whereas 1377 of these are defined by the DBpedia ontology.
Classes. Knowledge in Wikipedia is constantly growing at a rapid pace. We use the DBpedia Ontology Classes to measure the growth: Total number in this release (in brackets we give: a) growth to the previous release, which can be negative temporarily and b) growth compared to Snapshot 2016-10):
- Persons: 1792308 (1.01%, 1.13%)
- Places: 748372 (1.00%, 1820.86%), including but not limited to 590481 (1.00%, 5518.51%) populated places
- Works 610589 (1.00%, 619.89%), including, but not limited to
- 157566 (1.00%, 1.38%) music albums
- 144415 (1.01%, 15.94%) films
- 24829 (1.01%, 12.53%) video games
- Organizations: 345523 (1.01%, 109.31%), including but not limited to
- 87621 (1.01%, 2.25%) companies
- 64507 (1.00%, 64507.00%) educational institutions
- Species: 1933436 (1.01%, 322239.33%)
- Plants: 7718 (0.82%, 1.71%)
- Diseases: 10591 (1.00%, 8.54%)
Detailed Growth of Classes: The image below shows the detailed growth for one class. Click on the links for other classes: Place, PopulatedPlace, Work, Album, Film, VideoGame, Organisation, Company, EducationalInstitution, Species, Plant, Disease. For further classes adapt the query by replacing the <http://dbpedia.org/ontology/CLASS> URI. Note, that 2018 was a development phase with some failed extractions. The stats were generated with the Databus VOID Mod.
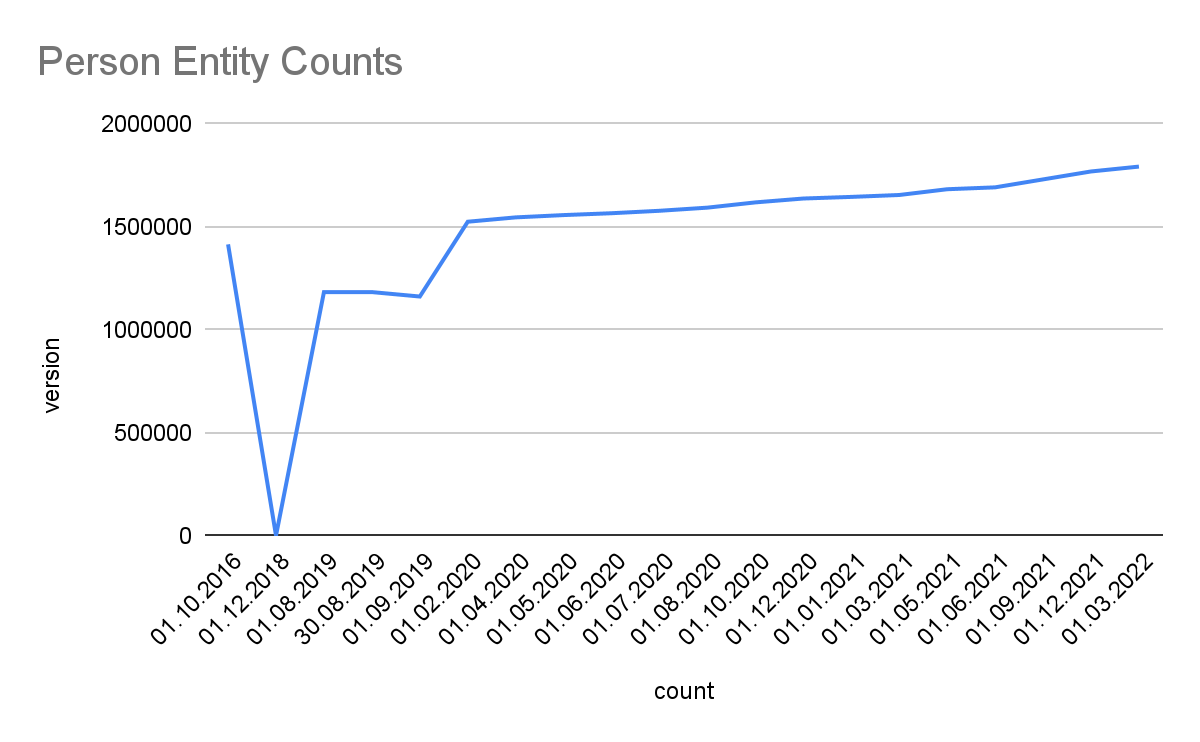
Links. Linked Data cross-references between decentral datasets are the foundation and access point to the Linked Data Web. The latest Snapshot Release provides over 130.6 million links from 7.62 million entities to 179 external sources.
Top 11
###TOP11###
33,573,926 http://www.wikidata.org
7,005,750 https://global.dbpedia.org
4,308,772 http://yago-knowledge.org
3,768,764 http://de.dbpedia.org
3,642,704 http://fr.dbpedia.org
2,946,265 http://viaf.org
2,872,878,344 http://it.dbpedia.org
2,853,081 http://es.dbpedia.org
2,651,369 http://fa.dbpedia.org
2,552,761 http://sr.dbpedia.org
2,517,456 http://ru.dbpedia.org
Top 10 without DBpedia namespaces
###TOP10###
33,573,926 http://www.wikidata.org
4,308,772 http://yago-knowledge.org
2,946,265 http://viaf.org
1,633,862 http://d-nb.info
601,227 http://sws.geonames.org
596,134 http://umbel.org
528,123 http://data.bibliotheken.nl
430,839 http://www.w3.org
373,293 http://musicbrainz.org
104,433 http://linkedgeodata.org
DBpedia Extraction Dumps on the Databus
All extracted files are reachable via the DBpedia account on the Databus. The Databus has two main structures:
- In groups, artifacts, version, similar to software in Maven: https://databus.dbpedia.org/$user/$group/$artifact/$version/$filename
- In Databus collections that are SPARQL queries over https://databus.dbpedia.org/yasui filtering and selecting files from these artifacts.
Snapshot Download. For downloading DBpedia Snapshot, we prepared this collection, which also includes detailed releases notes: https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2022-03
The collection is roughly equivalent to http://downloads.dbpedia.org/2016-10/core/
Collections can be downloaded in many different ways, some download modalities such as bash script, SPARQL, and plain URL list are found in the tabs at the collection. Files are provided as bzip2 compressed n-triples files. In case you need a different format or compression, you can also use the “Download-As” function of the Databus Client (GitHub), e.g. -s $collection -c gzip would download the collection and convert it to GZIP during download.
Replicating DBpedia Snapshot on your server can be done via Docker, , see https://hub.docker.com/r/dbpedia/virtuoso-sparql-endpoint-quickstart
git clone https://github.com/dbpedia/virtuoso-sparql-endpoint-quickstart.git
cd virtuoso-sparql-endpoint-quickstart
COLLECTION_URI=https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2022-03VIRTUOSO_ADMIN_PASSWD=password docker-compose up
Download files from the whole DBpedia extraction. The whole extraction consists of approx. 20 Billion triples and 5000 files created from 140 languages of Wikipedia, Commons and Wikidata. They can be found in https://databus.dbpedia.org/dbpedia/(generic|mappings|text|wikidata)
You can copy-edit a collection and create your own customized (e.g.) collections via “Actions” -> “Copy Edit” , e.g. you can Copy Edit the snapshot collection above, remove some files that you do not need and add files from other languages. Please see the Rhizomer use case: Best way to download specific parts of DBpedia. Of course, this only refers to the archived dumps on the Databus for users who want to bulk download and deploy into their own infrastructure. Linked Data and SPARQL allow for filtering the content using a small data pattern.
Acknowledgments
First and foremost, we would like to thank our open community of knowledge engineers for finding & fixing bugs and for supporting us by writing data tests. We would also like to acknowledge the DBpedia Association members for constantly innovating the areas of knowledge graphs and linked data and pushing the DBpedia initiative with their know-how and advice. OpenLink Software supports DBpedia by hosting SPARQL and Linked Data; University Mannheim, the German National Library of Science and Technology (TIB) and the Computer Center of University Leipzig provide persistent backups and servers for extracting data. We thank Marvin Hofer and Mykola Medynskyi for technical preparation. This work was partially supported by grants from the Federal Ministry for Economic Affairs and Energy of Germany (BMWi) for the LOD-GEOSS Project (03EI1005E), as well as for the PLASS Project (01MD19003D).
The post DBpedia Snapshot 2022-03 Release appeared first on DBpedia Association.
]]>The post DBpedia Snapshot 2021-12 Release appeared first on DBpedia Association.
]]>News since DBpedia Snapshot 2021-09
+ Release notes are now maintained in the Databus Collection (2021-12)
+ Image and Abstract Extractor was improved
+ Work in progress: Smoothing the community issue reporting and fixing at Github
What is the “DBpedia Snapshot” Release?
Historically, this release has been associated with many names: “DBpedia Core”, “EN DBpedia”, and — most confusingly — just “DBpedia”. In fact, it is a combination of —
- EN Wikipedia data — A small, but very useful, subset (~ 1 Billion triples or 14%) of the whole DBpedia extraction using the DBpedia Information Extraction Framework (DIEF), comprising structured information extracted from the English Wikipedia plus some enrichments from other Wikipedia language editions, notably multilingual abstracts in ar, ca, cs, de, el, eo, es, eu, fr, ga, id, it, ja, ko, nl, pl, pt, sv, uk, ru, zh.
- Links — 62 million community-contributed cross-references and owl:sameAs links to other linked data sets on the Linked Open Data (LOD) Cloud that allow to effectively find and retrieve further information from the largest, decentral, change-sensitive knowledge graph on earth that has formed around DBpedia since 2007.
- Community extensions — Community-contributed extensions such as additional ontologies and taxonomies.
Release Frequency & Schedule
Going forward, releases will be scheduled for the 15th of January, April, June and September (with +/- 5 days tolerance), and are named using the same date convention as the Wikipedia Dumps that served as the basis for the release. An example of the release timeline is shown below:
| December 6–8 | Dec 8–20 | Dec 20–Jan 15 | Jan 15–Feb 8 |
| Wikipedia dumps for June 1 become available on https://dumps.wikimedia.org/ | Download and extraction with DIEF | Post-processing and quality-control period | Linked Data and SPARQL endpoint deployment |
Data Freshness
Given the timeline above, the EN Wikipedia data of DBpedia Snapshot has a lag of 1-4 months. We recommend the following strategies to mitigate this:
- DBpedia Snapshot as a kernel for Linked Data: Following the Linked Data paradigm, we recommend using the Linked Data links to other knowledge graphs to retrieve high-quality and recent information. DBpedia’s network consists of the best knowledge engineers in the world, working together, using linked data principles to build a high-quality, open, decentralized knowledge graph network around DBpedia. Freshness and change-sensitivity are two of the greatest data-related challenges of our time, and can only be overcome by linking data across data sources. The “Big Data” approach of copying data into a central warehouse is inevitably challenged by issues such as co-evolution and scalability.
- DBpedia Live: Wikipedia is unmistakenly the richest, most recent body of human knowledge and source of news in the world. DBpedia Live is just minutes behind edits on Wikipedia, which means that as soon as any of the 120k Wikipedia editors press the “save” button, DBpedia Live will extract fresh data and update. DBpedia Live is currently in tech preview status and we are working towards a high-available and reliable business API with support. DBpedia Live consists of the DBpedia Live Sync API (for syncing into any kind of on-site databases), Linked Data and SPARQL endpoint.
- Latest-Core is a dynamically updating Databus Collection. Our automated extraction robot “MARVIN” publishes monthly dev versions of the full extraction, which are then refined and enriched to become Snapshot.
Data Quality & Richness
We would like to acknowledge the excellent work of Wikipedia editors (~46k active editors for EN Wikipedia), who are ultimately responsible for collecting information in Wikipedia’s infoboxes, which are refined by DBpedia’s extraction into our knowledge graphs. Wikipedia’s infoboxes are steadily growing each month and according to our measurements grow by 150% every three years. EN Wikipedia’s inboxes even doubled in this timeframe. This richness of knowledge drives the DBpedia Snapshot knowledge graph and is further potentiated by synergies with linked data cross-references. Statistics are given below.
Data Access & Interaction Options
Linked Data
Linked Data is a principled approach to publishing RDF data on the Web that enables interlinking data between different data sources, courtesy of the built-in power of Hyperlinks as unique Entity Identifiers.
HTML pages comprising Hyperlinks that confirm to Linked Data Principles is one of the methods of interacting with data provided by the DBpedia Snapshot, be it manually via the web browser or programmatically using REST interaction patterns via https://dbpedia.org/resource/{entity-label} pattern. Naturally, we encourage Linked Data interactions, while also expecting user-agents to honor the cache-control HTTP response header for massive crawl operations. Instructions for accessing Linked Data, available in 10 formats.
SPARQL Endpoint
This service enables some astonishing queries against Knowledge Graphs derived from Wikipedia content. The Query Services Endpoint that makes this possible is identified by http://dbpedia.org/sparql, and it currently handles 7.2 million queries daily on average. See powerful queries and instructions (incl. rates and limitations).
An effective Usage Pattern is to filter a relevant subset of entity descriptions for your use case via SPARQL and then combine with the power of Linked Data by looking up (or de-referencing) data via owl:sameAs property links en route to retrieving specific and recent data from across other Knowledge Graphs across the massive Linked Open Data Cloud.
Additionally, DBpedia Snapshot dumps and additional data from the complete collection of datasets derived from Wikipedia are provided by the DBpedia Databus for use in your own SPARQL-accessible Knowledge Graphs.
DBpedia Ontology
This Snapshot Release was built with DBpedia Ontology (DBO) version: https://databus.dbpedia.org/ontologies/dbpedia.org/ontology–DEV/2021.11.08-124002 We thank all DBpedians for the contribution to the ontology and the mappings. See documentation and visualizations, class tree and properties, wiki.
DBpedia Snapshot Statistics
Overview. Overall the current Snapshot Release contains more than 850 million facts (triples).
At its core, the DBpedia ontology is the heart of DBpedia. Our community is continuously contributing to the DBpedia ontology schema and the DBpedia infobox-to-ontology mappings by actively using the DBpedia Mappings Wiki.
The current Snapshot Release utilizes a total of 55 thousand properties, whereas 1377 of these are defined by the DBpedia ontology.
Classes. Knowledge in Wikipedia is constantly growing at a rapid pace. We use the DBpedia Ontology Classes to measure the growth: Total number in this release (in brackets we give: a) growth to the previous release, which can be negative temporarily and b) growth compared to Snapshot 2016-10):
- Persons: 1768613 (1.02%, 1.11%)
- Places: 745010 (1.01%, 1812.68%), including but not limited to 588283 (1.01%, 5497.97%) populated places
- Works 607852 (1.01%, 617.11%), including, but not limited to
- 157266 (1.00%, 1.38%) music albums
- 143193 (1.01%, 15.80%) films
- 24658 (1.01%, 12.44%) video games
- Organizations: 343109 (1.01%, 108.54%), including but not limited to
- 86950 (1.01%, 2.23%) companies
- 64539 (1.00%, 64539.00%) educational institutions
- Species: 1918094 (11.95%, 319682.33%)
- Plants: 9369 (0.89%, 2.07%)
- Diseases: 10553 (1.00%, 8.51%)
Detailed Growth of Classes: The image below shows the detailed growth for one class. Click on the links for other classes: Place, PopulatedPlace, Work, Album, Film, VideoGame, Organisation, Company, EducationalInstitution, Species, Plant, Disease. For further classes adapt the query by replacing the<http://dbpedia.org/ontology/CLASS> URI. Note, that 2018 was a development phase with some failed extractions. The stats were generated with the Databus VOID Mod.
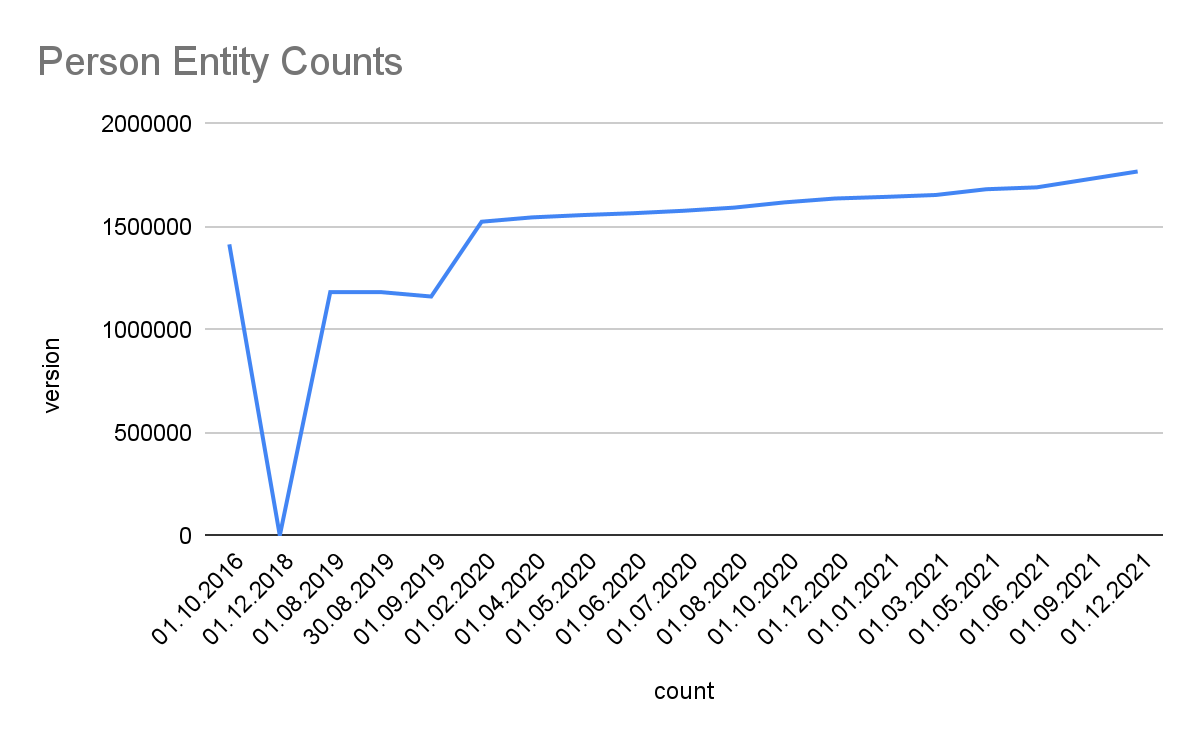
Links. Linked Data cross-references between decentral datasets are the foundation and access point to the Linked Data Web. The latest Snapshot Release provides over 129.9 million links from 7.54 million entities to 179 external sources.
Top 11
###TOP11###
33,522,731 http://www.wikidata.org
6,924,866 https://global.dbpedia.org
4,308,772 http://yago-knowledge.org
3,742,122 http://de.dbpedia.org
3,617,112 http://fr.dbpedia.org
3,067,339 http://viaf.org
2,860,142 http://it.dbpedia.org
2,841,468 http://es.dbpedia.org
2,609,236 http://fa.dbpedia.org
2,549,967 http://sr.dbpedia.org
2,496,247 http://ru.dbpedia.org
Top 10 without DBpedia namespaces
###TOP10###
33,522,731 http://www.wikidata.org
4,308,772 http://yago-knowledge.org
3,067,339 http://viaf.org
1,831,098 http://d-nb.info
641,602 http://sws.geonames.org
596,134 http://umbel.org
524,267 http://data.bibliotheken.nl
430,839 http://www.w3.org
370,844 http://musicbrainz.org
106,498 http://linkedgeodata.org
DBpedia Extraction Dumps on the Databus
All extracted files are reachable via the DBpedia account on the Databus. The Databus has two main structures:
- In groups, artifacts, version, similar to software in Maven: https://databus.dbpedia.org/$user/$group/$artifact/$version/$filename
- In Databus collections that are SPARQL queries over https://databus.dbpedia.org/yasui filtering and selecting files from these artifacts.
Snapshot Download. For downloading DBpedia Snapshot, we prepared this collection, which also includes detailed releases notes: https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2021-12
The collection is roughly equivalent to http://downloads.dbpedia.org/2016-10/core/.
Collections can be downloaded in many different ways, some download modalities such as bash script, SPARQL, and plain URL list are found in the tabs at the collection. Files are provided as bzip2 compressed n-triples files. In case you need a different format or compression, you can also use the “Download-As” function of the Databus Client (GitHub), e.g. –s $collection -c gzip would download the collection and convert it to GZIP during download.
Replicating DBpedia Snapshot on your server can be done via Docker, see https://hub.docker.com/r/dbpedia/virtuoso-sparql-endpoint-quickstart.
git clone https://github.com/dbpedia/virtuoso-sparql-endpoint-quickstart.git
cd virtuoso-sparql-endpoint-quickstart
COLLECTION_URI=https://databus.dbpedia.org/dbpedia/collections/dbpedia-snapshot-2021-12 VIRTUOSO_ADMIN_PASSWD=password docker-compose up
Download files from the whole DBpedia extraction. The whole extraction consists of approx. 20 Billion triples and 5000 files created from 140 languages of Wikipedia, Commons and Wikidata. They can be found in https://databus.dbpedia.org/dbpedia/(generic|mappings|text|wikidata)
You can copy-edit a collection and create your own customized (e.g.) collections via “Actions” -> “Copy Edit” , e.g. you can Copy Edit the snapshot collection above, remove some files that you do not need and add files from other languages. Please see the Rhizomer use case: Best way to download specific parts of DBpedia. Of course, this only refers to the archived dumps on the Databus for users who want to bulk download and deploy into their own infrastructure. Linked Data and SPARQL allow for filtering the content using a small data pattern.
Acknowledgments
First and foremost, we would like to thank our open community of knowledge engineers for finding & fixing bugs and for supporting us by writing data tests. We would also like to acknowledge the DBpedia Association members for constantly innovating the areas of knowledge graphs and linked data and pushing the DBpedia initiative with their know-how and advice.
OpenLink Software supports DBpedia by hosting SPARQL and Linked Data; University Mannheim, the German National Library of Science and Technology (TIB) and the Computer Center of University Leipzig provide persistent backups and servers for extracting data. We thank Marvin Hofer and Mykola Medynskyi for technical preparation. This work was partially supported by grants from the Federal Ministry for Economic Affairs and Energy of Germany (BMWi) for the LOD-GEOSS Project (03EI1005E), as well as for the PLASS Project (01MD19003D).
The post DBpedia Snapshot 2021-12 Release appeared first on DBpedia Association.
]]>The post 2021 – Oh What a Fantastic Year appeared first on DBpedia Association.
]]>In the upcoming blog series, we like to take you on a retrospective tour through 2021, giving you insights into a year with DBpedia. In the following we will also highlight our past events.
A year with DBpedia – Retrospective Part 1
Our New Face

On January 28, 2021, the new DBpedia website went online. We worked on the completion for about a year and at the beginning of 2021 we proudly presented the new site to the community and our members. We used the New Year’s break 2022/2021 as an opportunity to alter the layout, design and content of the website, according to the requirements of the community and our members. We’ve created a new site to better present the DBpedia movement in its many facets. We additionally integrated the DBpedia blog on the website, a long overdue step. So now, you have access to all in one spot. Read our announcement here.
Giving knowledge back to Wikipedia: Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources
Since the beginning of DBpedia, there was always a strong consensus in the community, that one of the goals of DBpedia was to feed semantic knowledge back into Wikipedia again to improve its structure and data quality. It was a topic of many discussions over the years about how to achieve this goal. We received a Wikimedia Grant for our project GlobalFactSyncRE and re-iterated the issue again. After almost two years of working on the topic, we would like to announce our final report. We submitted a summary of this report to the Qurator conference and presented it there on February 11, 2021:
Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources. Sebastian Hellmann, Johannes Frey, Marvin Hofer, Milan Dojchinovski, Krzysztof Wecel and Włodzimierz Lewoniewski.
Read the submitted paper here.
DBpedia Tutorial at the Knowledge Graph Conference

On May 4, 2021, we organized a tutorial at the Knowledge Graph Conference 2021. The tutorial targeted existing and potential new users and developers that wish to learn how to replicate our infrastructure. During the course of the tutorial the participants gained knowledge about the DBpedia Knowledge Graph (KG) lifecycle, how to find information, access, query and work with the DBpedia KG and the Databus platform as well as services (Spotlight, Archivo, etc). If you missed our presentations, please check our slides here.
Most Influential Scholars
DBpedia has become a high-impact, high-visibility project because of our foundation in excellent Knowledge Engineering as the pivot point between scientific methods, innovation and industrial-grade output. The drivers behind DBpedia are 4 out of the TOP 10 Most Influential Scholars in Knowledge Engineering and the C-level executives of our members. Check all details here https://www.aminer.cn/ai2000/ke.
Google Summer of Code and DBpedia
For the 10th year in a row, we were part of this incredible journey of young ambitious developers who joined us as an open source organization to work on a GSoC coding project all summer. Even though Covid-19 changed a lot in the world, it couldn’t shake GSoC. If you want to have deeper insights in our GSoC student’s work you can find their blogs and repos on the DBpedia blog.
DBpedia Global: Data Beyond Wikipedia
Since 2007, we’ve been extracting, mapping and linking content from Wikipedia into what is generally known as the DBpedia Snapshot that provided the kernel for what is known today as the LOD Cloud Knowledge Graph. On June 7, 2021, we launched DBpedia Global. It’s a more powerful kernel for LOD Cloud Knowledge Graph that ultimately strengthens the utility of Linked Data principles by adding more decentralization i.e., broadening the scope of Linked Data associated with DBpedia. Think of this as “DBpedia beyond Wikipedia” courtesy of additional reference data from various sources. Get more insight and read the announcement on the DBpedia blog.

In the upcoming blog post after the holidays we will give you more insights in the past events and technical achievements. We are now looking forward to the year 2022. We plan to have meetings at the Data Week 2022 in Leipzig, Germany and the SEMANTiCS 2022 conference in Vienna, Austria. Furthermore, we will be part of the WWW’22 conference and organize a tutorial.
We wish you a merry Christmas and a happy new year. In the meantime, stay tuned and check our Twitter, Instagram or LinkedIn channels. You can subscribe to our Newsletter for the latest news and information around DBpedia.
Julia,
on behalf of the DBpedia Association
The post 2021 – Oh What a Fantastic Year appeared first on DBpedia Association.
]]>The post Bringing Linked Data to the Domain Expert with TriplyDB Data Stories appeared first on DBpedia Association.
]]>by Kathrin Dentler, Triply
Triply and TriplyDB
Triply is an Amsterdam-based company with the mission to (help you to) make linked data the new normal. Every day, we work towards making every step around working with linked data easier, such as converting and publishing it, integrating, querying, exploring and visualising it, and finally sharing and (re-)using it. We believe in the benefits of FAIR (findable, accessible, interoperable and reusable) data and open standards. Our product, TriplyDB, is a user-friendly, performant and stable platform, designed for potentially very large linked data knowledge graphs in practical and large-scale production-ready applications. TriplyDB not only allows you to store and manage your data, but also provides data stories, a great tool for storytelling.
Data stories
Data stories are data-driven stories, such as articles, business reports or scientific papers, that incorporate live, interactive visualizations of the underlying data. They are written in markdown, and can be underpinned by an orchestration of powerful visualizations of SPARQL query results. These visualizations can be charts, maps, galleries or timelines, and they always reflect the current state of your data. That data is just one click away: A query in a data story can be tested or even tweaked by its readers. It is possible to verify, reproduce and analyze the results and therefore the narrative, and to download the results or the entire dataset. This makes a data story truly FAIR, understandable, and trustworthy. We believe that a good data story can be worth more than a million words.
Examples
With a data story, the domain expert is in control and empowered to work with, analyze, and share his or her data as well as interesting research results. There are some great examples that you can check out straight away:
- The fantastic data story on the Spanish Flu, which has been created by history and digital humanities researchers, who usually use R and share their results in scientific papers.
- Students successfully published data stories in the scope of a course of only 10 weeks.
- The beautiful data story on the Florentine Catasto of 1427.
DBpedia on triplydb.com
Triplydb.com is our public instance of TriplyDB, where we host many valuable datasets, which currently consist of nearly 100 billion triples. One of our most interesting and frequently used datasets are those by the DBpedia Association:
- a version from 2017 with 369.205.380 statements
- the DBpedia Snapshot 2021-06 Release with 845.807.279 statements, and
- a version of the DBpedia ontology
We also have several interesting saved queries based on these datasets.
A data story about DBpedia

To showcase the value of DBpedia and data stories to our users, we published a data story about DBpedia. This data story includes comprehensible and interactive visualizations, such as a timeline and a tree hierarchy, all of which are powered by live SPARQL queries against the DBpedia dataset.
Let us have a look at the car timeline: DBpedia contains a large amount of content regarding car manufacturers and their products. Based on that data, we constructed a timeline which shows the evolution within the car industry.

If you navigate from the data story to the query, you can analyze it and try it yourself. You see that the query limits the number of manufacturers so that we are able to look at the full scale of the automotive revolution without cluttering the timeline. You can play around with the query, change the ordering, visualize less or more manufacturers, or change the output format altogether.
Advanced features
If you wish to use a certain query programmatically, we offer preconfigured code snippets that allow you to run a query from a python or an R script. You can also configure REST APIs in case you want to work with variables. And last but not least, it is possible to embed a data story on any website. Just scroll to the end of the story you want to embed and click the “</> Embed” button for a copy-pasteable code snippet.
Try it yourself!
Sounds interesting? We still have a limited number of free user accounts over at triplydb.com. You can conveniently log in with your Google or Github account and start uploading your data. We host your first million open data triples for free! Of course, you can also use public datasets, such as the ones from DBpedia, link your data, work together on queries, save them, and then one day create your own data story to let your data speak for you. We are already looking forward to what your data has to say!
A big thank you to Triply for being a DBpedia member since 2020. Especially Kathrin Dentler for presenting her work at the last DBpedia Day in Amsterdam and for her amazing contribution to DBpedia.
Yours,
DBpedia Association
The post Bringing Linked Data to the Domain Expert with TriplyDB Data Stories appeared first on DBpedia Association.
]]>The post DBpedia Day – Hallo Gemeenschap! appeared first on DBpedia Association.
]]>First and foremost, we would like to thank the Institute for Applied Informatics for supporting our community and many thanks to the VU University Amsterdam and the SEMANTiCS organisation team for hosting this year’s DBpedia Day.
Opening of the DBpedia Day

Our CEO, Sebastian Hellmann, opened the DBpedia Day with an update about the DBpedia Databus and DBpedia members. He presented the huge and diverse network DBpedia has built up in the last 13 years. Afterwards, Maria-Esther Vidal, TIB, completed the opening session with her keynote “Enhancing Linked Data Trustability and Transparency through Knowledge-driven Data Ecosystems”. If you would like to get more insights, please find both slide decks here.
Member Presentation Session
Dennis Diefenbach, The QA Company, started the DBpedia member presentation session with his presentation “Question Answering over DBpedia”. Shortly after, Luke Feeney and Gavin Mendel-Gleason, TerminusDB, promoted the implementation of a cloud data mesh with a Knowledge Graph. Next, Russa Biswas, FIZ, talked about “Entity Type Prediction in DBpedia using Neural Networks”. Followed by another remote presentation by Ricardo Alonso Maturana and Susana López, Gnoss, presenting the “Didactalia Encyclopaedia”. They demonstrated a chronological, compared and contextual perspective of enriched and linked entities.
Afterwards, Antonia Donvito from FinScience explained how they use DBpedia Spotlight-a tool for automatically annotating mentions of DBpedia resources in text, providing a solution for linking unstructured information sources to the Linked Open Data cloud through DBpedia. Kathrin Dentler, Triply, talked about “Bringing linked data to the domain expert with TriplyDB data stories”. Closing the member session, Margaret Warren, ImageSnippets, presented “Anchoring Images to Meaning Using DBpedia” live via Zoom from Florida, U.S.
For further details of the presentations follow the links to the slides.
- “Question Answering over DBpedia” by Dennis Diefenbach, The QA Company (slides)
- Implementing a Cloud Data Mesh with a Knowledge Graph” by Luke Feeney and Gavin Mendel-Gleason, TerminusDB (slides)
- “Entity Type Prediction in DBpedia using Neural Networks” by Russa Biswas, FIZ Karlsruhe (slides)
- “Didactalia Encyclopaedia: a chronological, compared and contextual perspective of enriched and linked entities which presents a global view of human knowledge using semantic artificial intelligence” by Ricardo Alonso Maturana, GNOSS (slides)
- “DBpedia Spotlight @ FinScience: alternative data for fintech applications” by Antonia Donvito, FinScience (slides)
- “Bringing linked data to the domain expert with TriplyDB data stories” by Kathrin Dentler, Triply (slides)
- “Anchoring Images to Meaning Using DBpedia” by Margaret Warren, ImageSnippets (slides)
Ontology and NLP Sessions at the DBpedia Day
As a regular part of the DBpedia Community Meeting, we had two parallel sessions in the afternoon where DBpedians discussed most recent challenges in the context of DBpedia. Participants interested in NLP-related topics joined the NLP & DBpedia session. Milan Dojchinovski (InfAI, CTU Prague) chaired this session with four very stimulating talks. Hereafter you will find the presentations given during this session:
- “Zero-Shot Text Classification for Scholarly Data with DBpedia” by Fabian Hoppe, FIZ Karlsruhe (slides)
- “European network for Web-centred linguistic data science” by Jorge Gracia (University of Zaragoza) and Thierry Declerck, DFKI, Germany (slides)
- “Capturing the semantics of documentary evidence of humanities research” by Enrico Daga, KMi, The Open University, United Kingdom (slides)
- “NLP & DBpedia: Literature Review” by Artem Revenko, Semantic Web Company, Austria (slides)
At the same time, the DBpedia Ontology Session provided a platform for the community to discuss implementable criteria to evaluate ontologies, especially the ontology archive DBpedia Archivo. Hereafter you will find all presentations given during this session:
- “Introduction & Motivation” by Sebastian Hellmann, InfAI/DBpedia (slides)
- “Exploiting Semantic Knowledge Graphs to enable data integration and interoperability within the Agrifood sector” by Monika Solanki, Agrimetrics (slides)
- “DBpedia Archivo” by Denis Streitmatter, InfAI/AKSW (slides)
- “FOOPS! An Ontology Pitfall Scanner for the FAIR principles” by Daniel Garijo, UPM (slides)

Diversity of DBpedia – The DBpedia Language Chapters
This year’s DBpedia Day also covered a special chapter session, chaired by Enno Meijers, KB and Dutch DBpedia Language Chapter. Two speakers presented the latest technical and organizational developments of their respective chapters. Furthermore, Johannes Frey showcased the Dutch National Knowledge Graph (DNKG). During the DBpedia Autumn Hackathon 2020 the DBpedia team worked together with a group of Dutch organizations to explore the feasibility of building a DNKG. The knowledge graph was built from a number of authoritative datasets using the DBpedia Databus approach.
Following, you find a list of all presentations of this session:
- “Latest enhancements in the Spanish DBpedia” by Mariano Rico, Technical University of Madrid (UPM) (slides)
- “Creating the Hungarian DBpedia using the Databus” by Andras Micsik, SZTAKI (slides)
- “Dutch National Knowledge Graph pilot” by Johannes Frey, InfAI/DBpedia Association) (slides)
- Discussion about the future of the local DBpedia chapters lead by Enno Meijers
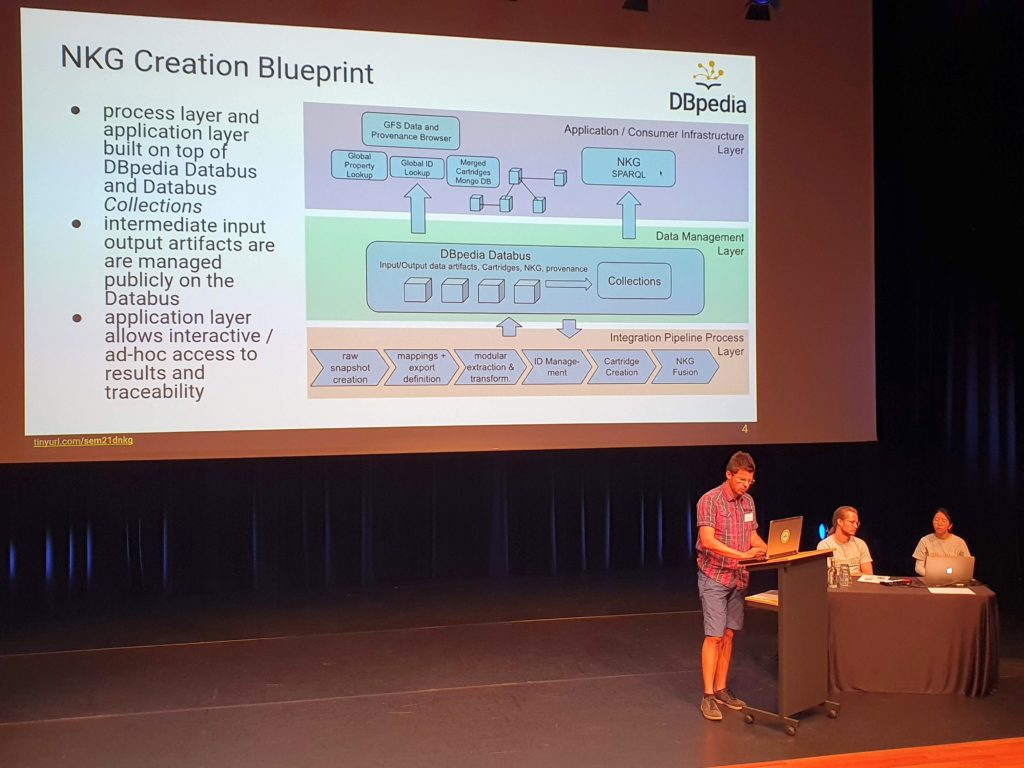
In this DBpedia chapter session we had a closer look at the results of the DNKG pilot. Furthermore, two DBpedia language chapters (Spanish and Hungarian) presented current developments and research results. Closing this session, Enno Meijers led a discussion about the opportunities of the DBpedia Databus for creating local chapters and building (national) knowledge graphs in general.
Summing up, the DBpedia Day at the SEMANTiCS conference brought together more than 100 DBpedia enthusiasts from Europe who engaged in vital discussions about Linked Data, the DBpedia archivo as well as DBpedia use cases and services.
In case you missed the event, all slides are also available on our event page. Further insights, feedback and photos about the event are available on Twitter via #DBpediaDay.
We are now looking forward to more DBpedia meetings in the next year. DBpedia will be part of the Connected Data World taking place online on December 1–3, 2021. We will organize a masterclass.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Julia
on behalf of the DBpedia Association
The post DBpedia Day – Hallo Gemeenschap! appeared first on DBpedia Association.
]]>The post A year with DBpedia – Retrospective Part 2/2020 appeared first on DBpedia Association.
]]>DBpedia Autumn Hackathon and the KGiA Conference
From September 21st to October 1st, 2020 we organized the first Autumn Hackathon. We invited all community members to join and contribute to this new format. You had the chance to experience the latest technology provided by the DBpedia Association members. We hosted special member tracks, a Dutch National Knowledge Graph Track and a track to improve DBpedia. Results were presented at the final hackathon event on October 5, 2020. We uploaded all contributions on our Youtube channel. Many thanks for all your contributions and invested time!
The Knowledge Graphs in Action event
The SEMANTiCS Onsite Conference 2020 had to be postponed till September 2021. To bridge the gap until 2021, we took the opportunity to organize the Knowledge Graphs in Action online track as a SEMANTiCS satellite event on October 6, 2020. This new online conference is a combination of two existing events: the DBpedia Community Meeting, which is regularly held as part of the SEMANTiCS, and the annual Spatial Linked Data conference organised by EuroSDR and the Platform Linked Data Netherlands. We glued it together and as a bonus we added a track about Geo-information Integration organized by EuroSDR. As special joint sessions we presented four keynote speakers. More than 130 knowledge graph enthusiasts joined the KGiA event and it was a great success for the organizing team. Do you miss the event? No problem! We uploaded all recorded sessions on the DBpedia youtube channel.
KnowConn Conference 2020
Our CEO, Sebastian Hellmann, gave the talk ‘DBpedia Databus – A platform to evolve knowledge and AI from versioned web files’ on December 2, 2020 at the KnowledgeConnexions Online Conference. It was a great success and we received a lot of positive and constructive feedback for the DBpedia Databus. If you missed his talk and looking for Sebastians slides, please check here: http://tinyurl.com/connexions-2020
DBpedia Archivo – Call to improve the web of ontologies
On December 7, 2020 we introduced the DBpedia Archivo – an augmented ontology archive and interface to implement FAIRer ontologies. Each ontology is rated with 4 stars measuring basic FAIR features. We would like to call on all ontology maintainers and consumers to help us increase the average star rating of the web of ontologies by fixing and improving its ontologies. You can easily check an ontology at https://archivo.dbpedia.org/info. Further infos on how to help us are available in a detailed post on our blog.
Member features on the blog
At the beginning of November 2020 we started the member feature on the blog. We gave DBpedia members the chance to present special products, tools and applications. We published several posts in which DBpedia members, like Ontotext, GNOSS, the Semantic Web Company, TerminusDB or FinScience shared unique insights with the community. In the beginning of 2021 we will continue with interesting posts and presentations. Stay tuned!
We do hope we will meet you and some new faces during our events next year. The DBpedia Association wants to get to know you because DBpedia is a community effort and would not continue to develop, improve and grow without you. We plan to have meetings in 2021 at the Knowledge Graph Conference, the LDK conference in Zaragoza, Spain and the SEMANTiCS conference in Amsterdam, Netherlands.
Happy New Year to all of you! Stay safe and check Twitter, LinkedIn and our Website or subscribe to our Newsletter for the latest news and information.
Yours,
DBpedia Association
The post A year with DBpedia – Retrospective Part 2/2020 appeared first on DBpedia Association.
]]>The post 2020 – Oh What a Challenging Year appeared first on DBpedia Association.
]]>In the upcoming Blog-Series, we like to take you on a retrospective tour through 2020, giving you insights into a year with DBpedia. We will highlight our past events and the development around the DBpedia dataset.
A year with DBpedia and the DBpedia dataset – Retrospective Part 1
DBpedia Workshop colocated with LDAC2020
On June 19, 2020 we organized a DBpedia workshop co-located with the LDAC workshop series to exchange knowledge regarding new technologies and innovations in the fields of Linked Data and Semantic Web. Dimitris Kontokostas (diffbot, US) opened the meeting with his delightful keynote presentation ‘{RDF} Data quality assessment – connecting the pieces’. His presentation focused on defining data quality and identification of data quality issues. Following Dimitri’s keynote many community based presentations were held, enabling an exciting workshop day.
Most Influential Scholars
DBpedia has become a high-impact, high-visibility project because of our foundation in excellent Knowledge Engineering as the pivot point between scientific methods, innovation and industrial-grade output. The drivers behind DBpedia are 6 out of the TOP 10 Most Influential Scholars in Knowledge Engineering and the C-level executives of our members. Check all details here: https://www.aminer.cn/ai2000/country/Germany
DBpedia (dataset) and Google Summer of Code 2020

For the 9th year in a row, we were part of this incredible journey of young ambitious developers who joined us as an open source organization to work on a GSoC coding project all summer. With 45 project proposals, this GSoC edition marked a new record for DBpedia. Even though Covid-19 changed a lot in the world, it couldn’t shake GSoC. If you want to have deeper insights in our GSoC student’s work you can find their blogs and repos here: https://blog.dbpedia.org/2020/10/12/gsoc2020-recap/.
DBpedia Tutorial Series 2020

During this year we organized three amazing tutorials in which more than 120 DBpedians took part. Over the last year, the DBpedia core team has consolidated a great amount of technology around DBpedia. These tutorials are target to developers (in particular of DBpedia Chapters) that wish to learn how to replicate local infrastructure such as loading and hosting an own SPARQL endpoint. A core focus was the new DBpedia Stack, which contains several dockerized applications that are automatically loading data from the DBpedia Databus. We will continue organizing more tutorials in 2021. Looking forward to meeting you online! In case you miss the DBpedia Tutorial series 2020, watch all videos here.
In our upcoming Blog-Post after the holidays we will give you more insights in past events and technical achievements. We are now looking forward to the year 2021. The DBpedia team plans to have meetings at the Knowledge Graph Conference, the LDK conference in Zaragoza, Spain and the SEMANTiCS conference in Amsterdam, Netherlands. We wish you a merry Christmas and a happy New Year. In the meantime, stay tuned and visit our Twitter channel or subscribe to our DBpedia Newsletter.
Yours DBpedia Association
The post 2020 – Oh What a Challenging Year appeared first on DBpedia Association.
]]>