The post DBpedia Day in Leipzig @ SEMANTiCS 2023 appeared first on DBpedia Association.
]]>First and foremost, we would like to thank the Institute for Applied Informatics for supporting our community and many thanks to the SEMANTiCS organization team for hosting this year’s community meeting.
Opening of the DBpedia Day

Also this year, our CEO Sebastian Hellmann opened the community meeting by presenting the Databus 2.1.0 project (slides). Afterwards, Edward Curry from the University of Galway gave his fantastic keynote presentation “Towards Foundation Models for Data Spaces”. You can read his abstract here.
Member Presentation Session

Milan Dojchinovski, InfAI/DBpedia Association and CTU Prague, started the member presentation session with a short welcome. The first speaker was Angel Moreno, GNOSS, with his presentation “NEURALIA Rioja: the unified Knowledge Graph of La Rioja Government which integrates twenty six sources of information in a single access point” (slides). Shortly after, Enno Meijers, KB, talked about “Network-of-Terms, bringing links to your data” (slides). Next, Sarah Binta Alam Shoilee, Network Institute & Vrije Universiteit Amsterdam talked about ”Cultural AI Lab”(slides). This was followed by the presentation “Linking and Consumption of DBpedia in TriplyDB” by Kathrin Dentler & Wouter Beek, TriplyDB (slides). Then Sebastian Gabler, SWC, talked about “Using Dewey Decimal Classification for linked data” (slides). Finally, the last talk of this session was given by Sebastian Tramp, eccenca, with “Using DBpedia Services with eccenca Corporate Memory and eccenca.my”.
For further details of the presentations follow the links to the slides.
- “NEURALIA Rioja: the unified Knowledge Graph of La Rioja Government which integrates twenty six sources of information in a single access point” by Angel Moreno, GNOSS (slides)
- “Network-of-Terms, bringing links to your data” by Enno Meijers, KB (slides)
- ”Cultural AI Lab” by Sarah Binta Alam Shoilee, Network Institute & Vrije Universiteit Amsterdam (slides)
- “Linking and Consumption of DBpedia in TriplyDB” by Kathrin Dentler & Wouter Beek, TriplyDB (slides)
- “Using Dewey Decimal Classification for linked data” by Sebastian Gabler, SWC (slides)
- “Using DBpedia Services with eccenca Corporate Memory and eccenca.my” by Sebastian Tramp, eccenca (slides)
DBpedia Science: Linking and Consumption

This session was dedicated to the most recent research on linking and consumption of the DBpedia Knowledge Graph and beyond. Novel methods, tools and challenges around linking and consumption of knowledge graphs were presented and discussed. Milan Dojchinovski, InfAI/DBpedia Association and CTU Prague, chaired this session with five talks. Hereafter you will find the presentations given during this session:
- “Open Research Knowledge Graph” by Sören Auer, TIB
- “Blocking Methods for Entity Resolution on Knowledge Graphs” by Daniel Obraczka, Data Science Center ScaDS.AI Dresden/Leipzig (slides)
- “Validating SHACL Constraints with Reasoning: Lessons Learned from DBpedia” by Maribel Acosta, TUM School of Computation, Information and Technology
- “Exploiting Semi-Structured Information in Wikipedia for Knowledge Graph Construction” by Nicolas Heist, Data and Web Science Group, University of Mannheim (slides)
- “Using Pre-trained Language Models for Abstractive DBpedia Summarization” by Hamada Zahera, Data Science Group, Paderborn University (slides)
DBpedia Community session
Sebastian Hellmann, InfAI/DBpedia Association, hosted this year’s community session. DBpedia has had a major impact on data landscape during our 15-year journey. This session discussed the progress of the vision of a “Global and Unified Access to Knowledge Graphs”, which paved the way for an international FAIR Open Data Space driven by knowledge graphs. The session focused on the potential of large-scale knowledge graphs to reshape the open data domain. Topics included how the DBpedia community can pool its data, tools and know-how more effectively, and how we can make these assets more findable, accessible and interoperable. The session provided an insightful discourse on the future of open data and how we can forge strategic alliances across diverse industrial sectors.
Following, you find the presentations of this session:
- “Update Japanese DBpedia” Hideaki Takeda, LODI (slides)
- Several impulses about different topics and follow-up discussion, moderated by Sebastian Hellmann, InfAI/DBpedia Association (discussion document)
In case you missed the event, all slides are also available on our event page. Further insights, feedback and photos about the event are available on Twitter via #DBpediaDay.
We are now looking forward to more DBpedia events in the upcoming months and at next year’s SEMANTiCS Conference, which will be held in Amsterdam, Netherlands.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Maria & Julia
on behalf of the DBpedia Association
The post DBpedia Day in Leipzig @ SEMANTiCS 2023 appeared first on DBpedia Association.
]]>The post Retrospective 2023 – Half a year with DBpedia appeared first on DBpedia Association.
]]>DBpedia is part of the Google Summer of Code project 2023

So far, each year has brought us new project ideas, many amazing students and great project results that shaped the future of DBpedia. Like every year, we received many fantastic applications this year. Out of these applications 6 great projects from contributors all over the world were selected to work together with our mentors. Right now the contributors are in the middle of the coding phase. If you want to know more about this year’s projects go and have a look at the DBpedia blog.
DBpedia Snapshot 2022-12 Release
We are pleased to announce immediate availability of a new edition of the free and publicly accessible Sparql Query Service Endpoint and Linked Data pages, for interacting with the new Snapshot Dataset. Check our blog!
Leipzig Semantic Web Day
On June 28, 2023, Sebastian Hellmann presented the DBpedia Databus 2.1. at Data Week Leipzig. Data Week is the networking and exchange event for highlighting scientific, economic, and social perspectives of data and its use, where industry, citizens, science, and public authorities can enter into dialogue. Data Week Leipzig took place June 26-30, 2023. Please find Sebastian’s slides here.
What Will the Future Bring?
We are now looking forward to the LDK conference, which will take place September 12-15, 2023, in Vienna, Austria. Will will organize a tutorial on September 13, 2023. If you would like to join, please check more details on our event page. After that, we’ll fly straight back to Leipzig, because the Semantics Conference will be held at the Hyperion Hotel Leipzig from September 20 to 22, 2023. At the beginning of the conference, we will host the DBpedia Day on September 20, 2023.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our newsletter for the latest news and information around DBpedia.
Julia
on behalf of the DBpedia Association
The post Retrospective 2023 – Half a year with DBpedia appeared first on DBpedia Association.
]]>The post Wrap Up: DBpedia Tutorial 2.0 @ Knowledge Graph Conference 2022 appeared first on DBpedia Association.
]]>Following, we will give you a brief retrospective about the tutorial. For further details of the presentations follow the link to the slides.
Session 1: DBpedia in a Nutshell
The tutorial was opened by Milan Dojchinovski (InfAI / DBpedia Association / CTU in Prague) with the DBpedia in a Nutshell session. In a 45 min session Milan presented a DBpedia historical Wrap-up, explained how a DBpedia triple is born as well as demonstrated the power of SPARQL and the DBpedia KG.
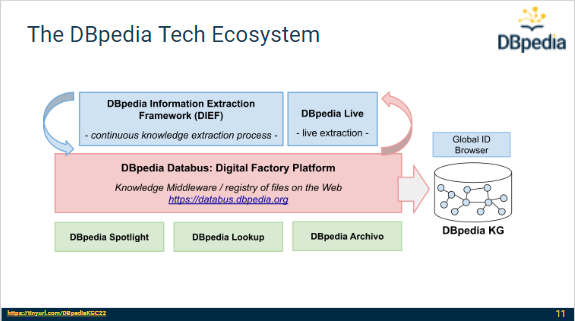
Session 2: DBpedia Tech Stack
After a short break, Jan started the DBpedia Tech Stack Session by giving an overview about the DBpedia technology stack. Furthermore, he explained the use of DBpedia for Automatization and Data Pipeline Creation. This included an explanation of Databus, possible ways to automate data tasks and examples such as knowledge extraction and knowledge fusion. After that, he got to the creation of a simple data flow using the Databus. This was about creation of new data, publishing the data on the Databus, aggregation and usage in SPARQL service via docker.
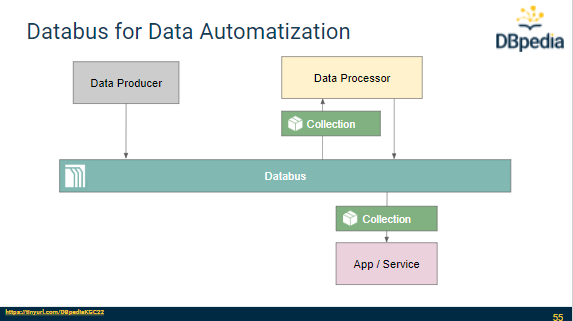
Session 3: Deployment on corporate infrastructure
In the third session Johannes started by presenting technical details in relation to Databus like identifiers, DataIDs and Mods. He also addressed DBpedia Databus popular datasets, where to find DBpedia datasets, how the DBpedia KG partitions are organized as well as popular data collections. As the tutorial came to an end, he explained how to self-host critical services including creation of a custom copy of the latest-core collection, (i.e. a subset of the DBpedia KG) and how to set up a corporate Databus instance.
In case you missed the event, our presentation is also available on the DBpeda event page. Further insights, feedback and photos about the event are available on Twitter (#DBpediaTutorial hashtag).
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Yours DBpedia Association
The post Wrap Up: DBpedia Tutorial 2.0 @ Knowledge Graph Conference 2022 appeared first on DBpedia Association.
]]>The post GSoC2022 – Call for Contributors appeared first on DBpedia Association.
]]>Brain: Wear a mask, keep our distance, and do the same thing we do every year, Pinky. Taking over GSoC2022.
For the 11th year in a row, we have been accepted to be part of this incredible program to support young ambitious developers who want to work with open-source organizations like DBpedia.
So far, each year has brought us new project ideas, many amazing students and great project results that shaped the future of DBpedia. Even though Covid-19 changed a lot in the world, it couldn’t shake Google Summer of Code (GSoC) much. The program, designed to mentor youngsters from afar is almost too perfect for us. One of the advantages of GSoC is, especially in times like these, the chance to work on projects remotely, but still obtain a first deep dive into Open Source projects like us.
DBpedia is now looking for contributors who want to work with us during the upcoming summer months.
What is Google Summer of Code?
Google Summer of Code is a global program focused on bringing developers into open source software development. Funds will be given to all new beginner contributors to open source over 18 years to work for two and a half months (or longer) on a specific task. For GSoC-Newbies, this short video and the information provided on their website will explain all there is to know about GSoC2022.
And this is how it works …
| Step 1 | Check out one of our projects here or draft your own. |
| Step 2 | Get in touch with our mentors as soon as possible and write up a project proposal of at least 8 pages. Information about our proposal structure and a template are available here. |
| Step 3 | After a selection phase, contributors are matched with a specific project and mentor(s) and start working on the project. |
Application Procedure
Further information on the application procedure is available in our DBpedia Guidelines. There you will find information on how to contact us and how to appropriately apply for GSoC2022. Please also note the official GSoC 2022 timeline for your proposal submission and make sure to submit on time. Unfortunately, extensions cannot be granted. Final submission deadline is April 19, 2022 at 18:00 UTC.
Contact
Detailed information on how to apply are available on the DBpedia website. We’ve prepared an information kit for you. Please find all necessary information regarding the student application procedure here.
And in case you still have questions, please do not hesitate to contact us via dbpedia@infai.org.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Finally, we are looking forward to your contribution!
Yours DBpedia Association
The post GSoC2022 – Call for Contributors appeared first on DBpedia Association.
]]>The post A year with DBpedia – Retrospective Part 2/2021 appeared first on DBpedia Association.
]]>LSWT 2021

We kicked-off the summer with an online tutorial at the Leipziger Semantic Web Day (LSWT). For the first time ever the LSWT team extended the program and organized a second conference day for DBpedia enthusiasts. Many thanks to the hosts and organizing team! It was a pleasure to be part of the LSWT again.If you were unable to take part in the tutorial, please check our slides here or watch the video on the DBpedia Youtube channel.
DBpedia Snapshot 2021-06 Release
On 23rd of July, 2021 we announced the DBpedia Snapshot 2021-06 Release. Historically, this release has been associated with many names: “DBpedia Core”, “EN DBpedia”, and — most confusingly — just “DBpedia”. In fact, it is a combination of the EN Wikipedia data, 62 million community-contributed cross-references links as well as community extensions such as additional ontologies and taxonomies. Read the announcement on the blog.
Tutorial at the LDK Conference and DBpedia Day at the SEMANTiCS Conference
At the beginning of September 2021 we jumped on a plane and gave a tutorial at the Language, Data and Knowledge (LDK) conference in Zaragoza, Spain. Building upon the success of the previous events held in Galway, Ireland in 2017, and in Leipzig, Germany in 2019, the conference brought together researchers from across disciplines concerned with the acquisition, curation and use of language data in the context of data science and knowledge-based applications. This tutorial was a great success and if you would like to catch up and check our slides, please click https://tinyurl.com/TutAtLDK. Few days later we travelled to Amsterdam, The Netherlands, to join this year’s SEMANTiCS Conference.

The DBpedia Day was part of the conference and was held on the last day of the conference on 9th of September at the Theater de Meervaart. Our CEO, Sebastian Hellmann, opened the DBpedia Day with an update about the DBpedia Databus and our members. He presented the huge and diverse network DBpedia has built up in the last 13 years. Afterwards, Maria-Esther Vidal, TIB, completed the opening session with her keynote “Enhancing Linked Data Trustability and Transparency through Knowledge-driven Data Ecosystems”. Furthermore, we organized a member presentation session, an ontology and a NLP session, where experts presented NLP and DBpedia-related topics. In case you missed the event, all slides are also available on our event page. Further insights, feedback and photos about the event are available on Twitter via #DBpediaDay.
Member Features on the Blog
At the beginning of November 2020 we started the member feature on our blog. In 2021 we continued and published further interesting posts and news about our members. We gave our members the chance to present special products, tools and applications. We published several posts in which members, i.e.Triply, WorldLift, Wallscope, eccenca, Diffbot, and the Network Institute (NI) of VU Amsterdam, shared unique insights with the community. Next year we will continue with interesting posts and presentations. Stay tuned!
DBpedia Snapshot 2021-09 Release
On October 22, 2021 we announced the immediate availability of a new edition of the free and publicly accessible SPARQL Query Service Endpoint and Linked Data Pages, for interacting with the new Snapshot Dataset. Since the last release we made a few changes. Release notes are now maintained in the Databus collection (2021-09), we improved the image and abstract extractor and the DBpedia team worked on the community issue reporting and fix tracker at Github. The full release description including further statistics can be found on https://www.dbpedia.org/blog/snapshot-2021-09-release/.

DBpedia Knowledge Graph Tutorial for Beginners
On 2nd of December, 2021 we organized the masterclass “Knowledge Graph tutorial for beginners” at the Connected Data World event. In this masterclass, participants learned how to consume the DBpedia Knowledge Graph with the least amount of effort. Furthermore, the masterclass introduced the DBpedia KG and we explained its dataset partitions. In case you missed the event, please watch the recorded session here.
We do hope we will meet you and some new faces during our events next year. The association wants to get to know you because DBpedia is a community effort and would not continue to develop, improve and grow without you. We plan to have meetings or tutorials at the Data Week in Leipzig, the Web Conference’22, and the SEMANTiCS’22 conference. We wish you a happy New Year!
Stay safe and check Twitter, Instagram and LinkedIn or or subscribe to our Newsletter for the latest news and information.
Yours,
Julia
on behalf of the DBpedia Association
The post A year with DBpedia – Retrospective Part 2/2021 appeared first on DBpedia Association.
]]>The post 2021 – Oh What a Fantastic Year appeared first on DBpedia Association.
]]>In the upcoming blog series, we like to take you on a retrospective tour through 2021, giving you insights into a year with DBpedia. In the following we will also highlight our past events.
A year with DBpedia – Retrospective Part 1
Our New Face

On January 28, 2021, the new DBpedia website went online. We worked on the completion for about a year and at the beginning of 2021 we proudly presented the new site to the community and our members. We used the New Year’s break 2022/2021 as an opportunity to alter the layout, design and content of the website, according to the requirements of the community and our members. We’ve created a new site to better present the DBpedia movement in its many facets. We additionally integrated the DBpedia blog on the website, a long overdue step. So now, you have access to all in one spot. Read our announcement here.
Giving knowledge back to Wikipedia: Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources
Since the beginning of DBpedia, there was always a strong consensus in the community, that one of the goals of DBpedia was to feed semantic knowledge back into Wikipedia again to improve its structure and data quality. It was a topic of many discussions over the years about how to achieve this goal. We received a Wikimedia Grant for our project GlobalFactSyncRE and re-iterated the issue again. After almost two years of working on the topic, we would like to announce our final report. We submitted a summary of this report to the Qurator conference and presented it there on February 11, 2021:
Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources. Sebastian Hellmann, Johannes Frey, Marvin Hofer, Milan Dojchinovski, Krzysztof Wecel and Włodzimierz Lewoniewski.
Read the submitted paper here.
DBpedia Tutorial at the Knowledge Graph Conference

On May 4, 2021, we organized a tutorial at the Knowledge Graph Conference 2021. The tutorial targeted existing and potential new users and developers that wish to learn how to replicate our infrastructure. During the course of the tutorial the participants gained knowledge about the DBpedia Knowledge Graph (KG) lifecycle, how to find information, access, query and work with the DBpedia KG and the Databus platform as well as services (Spotlight, Archivo, etc). If you missed our presentations, please check our slides here.
Most Influential Scholars
DBpedia has become a high-impact, high-visibility project because of our foundation in excellent Knowledge Engineering as the pivot point between scientific methods, innovation and industrial-grade output. The drivers behind DBpedia are 4 out of the TOP 10 Most Influential Scholars in Knowledge Engineering and the C-level executives of our members. Check all details here https://www.aminer.cn/ai2000/ke.
Google Summer of Code and DBpedia
For the 10th year in a row, we were part of this incredible journey of young ambitious developers who joined us as an open source organization to work on a GSoC coding project all summer. Even though Covid-19 changed a lot in the world, it couldn’t shake GSoC. If you want to have deeper insights in our GSoC student’s work you can find their blogs and repos on the DBpedia blog.
DBpedia Global: Data Beyond Wikipedia
Since 2007, we’ve been extracting, mapping and linking content from Wikipedia into what is generally known as the DBpedia Snapshot that provided the kernel for what is known today as the LOD Cloud Knowledge Graph. On June 7, 2021, we launched DBpedia Global. It’s a more powerful kernel for LOD Cloud Knowledge Graph that ultimately strengthens the utility of Linked Data principles by adding more decentralization i.e., broadening the scope of Linked Data associated with DBpedia. Think of this as “DBpedia beyond Wikipedia” courtesy of additional reference data from various sources. Get more insight and read the announcement on the DBpedia blog.

In the upcoming blog post after the holidays we will give you more insights in the past events and technical achievements. We are now looking forward to the year 2022. We plan to have meetings at the Data Week 2022 in Leipzig, Germany and the SEMANTiCS 2022 conference in Vienna, Austria. Furthermore, we will be part of the WWW’22 conference and organize a tutorial.
We wish you a merry Christmas and a happy new year. In the meantime, stay tuned and check our Twitter, Instagram or LinkedIn channels. You can subscribe to our Newsletter for the latest news and information around DBpedia.
Julia,
on behalf of the DBpedia Association
The post 2021 – Oh What a Fantastic Year appeared first on DBpedia Association.
]]>The post How Innovative Organizations Use The World’s Largest Knowledge Graph appeared first on DBpedia Association.
]]>by Filipe Mesquita & Merrill Cook, Diffbot

Diffbot is on a mission to create a knowledge graph of the entire public web. We are teaching a robot, affectionately known as Diffy, to read the web like a human and translate its contents into a format that (other perhaps less sophisticated) machines can understand. All of this information is linked and cleaned on a continuous basis to populate the Diffbot Knowledge Graph.
The Diffbot Knowledge Graph already contains billions of entities, including over 240M organizations, 700M people, 140M products, and 1.6B news articles. This scale is only possible because Diffy is fully autonomous and doesn’t depend on humans to build the Diffbot Knowledge Graph. Using cutting-edge crawling technology, natural language processing, and computer vision, Diffy is able to read and extract facts from across the entire web.
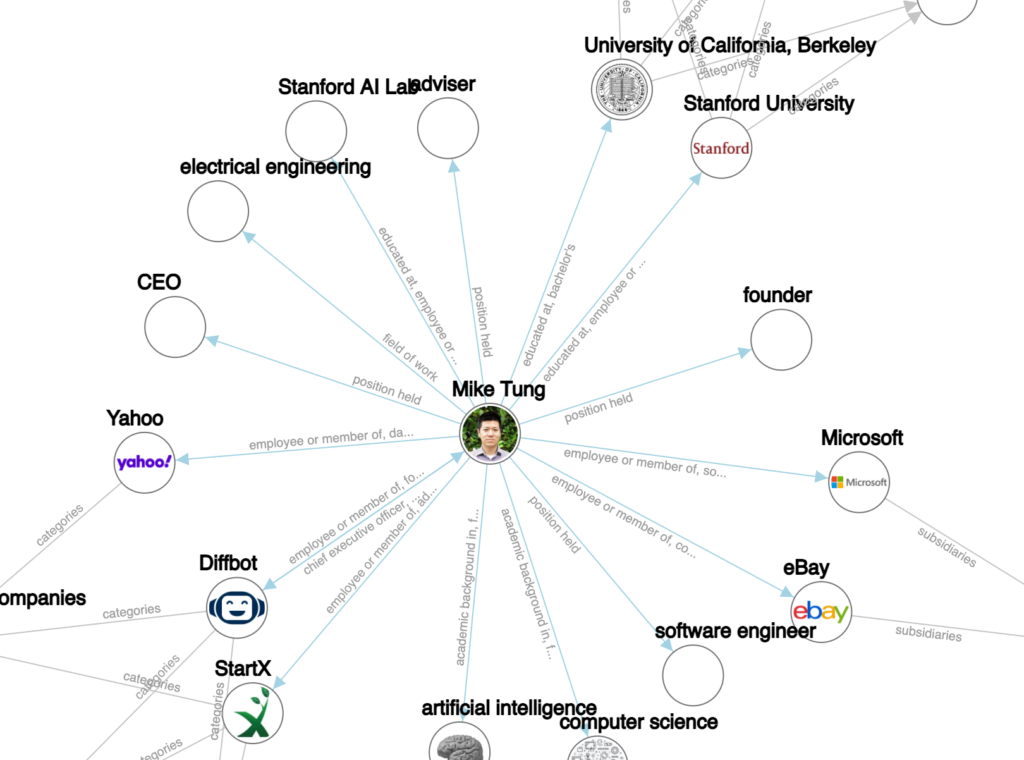
While we believe a knowledge graph like Diffbot’s will be used by virtually every organization one day, there are 4 use cases where the Diffbot Knowledge Graph excels today: (1) Market Intelligence, (2) News Monitoring, (3) E-commerce, and (4) Machine learning.
Market Intelligence

Video: https://www.diffbot.com/assets/video/solutions-for-media-monitoring.mp4
At its simplest, market intelligence is the generation of insights about participants in a market. These can include customers, suppliers, competitors, as well as attitudes of the general public and political establishment.
While market intelligence data is all over the public web, this can be a “double-edged sword.” The range of potential sources for market intelligence data can exhaust the resources of even large teams performing manual fact accumulation.
Diffbot’s automated web data extraction eliminates the inefficiencies of manual fact gathering. Without such automation, it’s simply not possible to monitor everything about a company across the web.
We see market intelligence as one of the most well-developed use cases for the Diffbot Knowledge Graph. Here’s why:
- The Diffbot Knowledge Graph is built around organizations, people, news articles, products, and the relationships among them. These are the types of facts that matter in market intelligence.
- Knowledge graphs have flexible schemas, allowing for new fact types to be added “on the fly” as the things we care about in the world change
- Knowledge graphs provide unique identifiers for all entities, supporting the disambiguation entities like Apple (the company) vs apple (the fruit).
Market intelligence uses from our customers include:
- Querying the Knowledge Graph for companies that fit certain criteria (size, revenue, industry, location) rather than manually searching for them in Google
- Creating dashboards to receive insights about companies in a certain industry
- Improving an internal database by using the data from the Diffbot Knowledge Graph.
- Custom solutions that incorporate multiple Diffbot products (custom web crawling, natural language processing, and Knowledge Graph data consumption)
News Monitoring
Sure, the news is all around us. But most companies are overwhelmed by the sheer amount of information produced every day that can impact their business.
The challenges faced by those trying to perform news monitoring on unstructured article data are numerous. Articles are structured differently across the web, making aggregation of diverse sources difficult. Many sources and aggregators silo their news by geographic location or language.
Strengths of providing article data through a wider Knowledge Graph include the ability to link articles to the entities (people, organizations, locations, etc) mentioned in each article. Additional natural language processing includes the ability to identify quotes and who said them as well as the sentiment of the article author towards each entity mentioned in the article.
In high-velocity, socially-fueled media, the need for automated analysis of information in textual form is even more pressing. Among the many applications of our technology, Diffbot is helping anti-bias and misinformation initiatives with partnerships involving FactMata as well as the European Journalism Centre.

Check out how easy it is to build your own custom pan-lingual news feed in our news feed builder.
Ecommerce
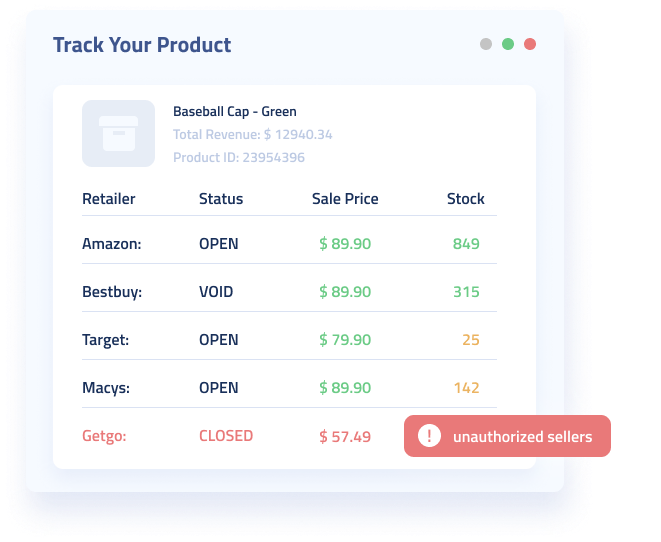
Many of the largest names in ecommerce have utilized Diffbot’s ability to transform unstructured product, review, and discussion data into valuable ecommerce intelligence. Whether pointing AI-enabled crawlers at their own marketplaces to detect fraudulent, duplicate, or underperforming products, or by analyzing competitor or supplier product listings.
One of the benefits of utilizing Diffbot’s AI-enabled product API or our product entities within the Knowledge Graph is the difficulty of scraping product data at scale. Many ecommerce sites employ active measures to make the scraping of their pages at scale difficult. We’ve already built out the infrastructure and can begin returning product data at scale in minutes.
The use of rule-based scraping by many competitors or in-house teams means that whenever ecommerce sites shift their layout or you try to extract ecommerce web data from a new location, your extraction method is likely to break. Additionally, hidden or toggleable fields on many ecommerce pages are more easily extracted by solutions with strong machine vision capabilities.
Diffbot’s decade-long focus on natural language processing also allows the inclusion of rich discussion data parsed for entities, connections, and sentiment. On large ecommerce sites, the structuring and additional processing of review data can be a large feat and provide high value.
Machine Learning

Even when you can get your hands on the right raw data to train machine learning models, cleaning and labeling the data can be a costly process. To help with this, Diffbot’s Knowledge Graph provides potentially the largest selection of once unstructured web data, complete with data provenance and confidence scores for each fact.
Our customers use a wide range of web data to quickly and accurately train models on diverse data types. Need highly informal text input from reviews? Video data in a particular language? Product or firmographic data? It’s all in the Knowledge Graph, structured and with API access so customers can quickly jump into validating new models.
With a long association with Stanford University and many research partnerships, Diffbot’s experts in web-scale machine learning work in tandem with many customers to create custom solutions and mutually beneficial partnerships.
To some, 2020 was the year of the knowledge graph. And while innovative organizations have long seen the benefits of graph databases, recent developments in the speed of fact accumulation online mean the future of graphs has never been more bright.
A big thank you to Diffbot, especially to Filipe Mesquita and Merrill Cook for presenting the Diffbot Knowledge Graph.
Yours,
DBpedia Association
The post How Innovative Organizations Use The World’s Largest Knowledge Graph appeared first on DBpedia Association.
]]>The post DBpedia Day – Hallo Gemeenschap! appeared first on DBpedia Association.
]]>First and foremost, we would like to thank the Institute for Applied Informatics for supporting our community and many thanks to the VU University Amsterdam and the SEMANTiCS organisation team for hosting this year’s DBpedia Day.
Opening of the DBpedia Day

Our CEO, Sebastian Hellmann, opened the DBpedia Day with an update about the DBpedia Databus and DBpedia members. He presented the huge and diverse network DBpedia has built up in the last 13 years. Afterwards, Maria-Esther Vidal, TIB, completed the opening session with her keynote “Enhancing Linked Data Trustability and Transparency through Knowledge-driven Data Ecosystems”. If you would like to get more insights, please find both slide decks here.
Member Presentation Session
Dennis Diefenbach, The QA Company, started the DBpedia member presentation session with his presentation “Question Answering over DBpedia”. Shortly after, Luke Feeney and Gavin Mendel-Gleason, TerminusDB, promoted the implementation of a cloud data mesh with a Knowledge Graph. Next, Russa Biswas, FIZ, talked about “Entity Type Prediction in DBpedia using Neural Networks”. Followed by another remote presentation by Ricardo Alonso Maturana and Susana López, Gnoss, presenting the “Didactalia Encyclopaedia”. They demonstrated a chronological, compared and contextual perspective of enriched and linked entities.
Afterwards, Antonia Donvito from FinScience explained how they use DBpedia Spotlight-a tool for automatically annotating mentions of DBpedia resources in text, providing a solution for linking unstructured information sources to the Linked Open Data cloud through DBpedia. Kathrin Dentler, Triply, talked about “Bringing linked data to the domain expert with TriplyDB data stories”. Closing the member session, Margaret Warren, ImageSnippets, presented “Anchoring Images to Meaning Using DBpedia” live via Zoom from Florida, U.S.
For further details of the presentations follow the links to the slides.
- “Question Answering over DBpedia” by Dennis Diefenbach, The QA Company (slides)
- Implementing a Cloud Data Mesh with a Knowledge Graph” by Luke Feeney and Gavin Mendel-Gleason, TerminusDB (slides)
- “Entity Type Prediction in DBpedia using Neural Networks” by Russa Biswas, FIZ Karlsruhe (slides)
- “Didactalia Encyclopaedia: a chronological, compared and contextual perspective of enriched and linked entities which presents a global view of human knowledge using semantic artificial intelligence” by Ricardo Alonso Maturana, GNOSS (slides)
- “DBpedia Spotlight @ FinScience: alternative data for fintech applications” by Antonia Donvito, FinScience (slides)
- “Bringing linked data to the domain expert with TriplyDB data stories” by Kathrin Dentler, Triply (slides)
- “Anchoring Images to Meaning Using DBpedia” by Margaret Warren, ImageSnippets (slides)
Ontology and NLP Sessions at the DBpedia Day
As a regular part of the DBpedia Community Meeting, we had two parallel sessions in the afternoon where DBpedians discussed most recent challenges in the context of DBpedia. Participants interested in NLP-related topics joined the NLP & DBpedia session. Milan Dojchinovski (InfAI, CTU Prague) chaired this session with four very stimulating talks. Hereafter you will find the presentations given during this session:
- “Zero-Shot Text Classification for Scholarly Data with DBpedia” by Fabian Hoppe, FIZ Karlsruhe (slides)
- “European network for Web-centred linguistic data science” by Jorge Gracia (University of Zaragoza) and Thierry Declerck, DFKI, Germany (slides)
- “Capturing the semantics of documentary evidence of humanities research” by Enrico Daga, KMi, The Open University, United Kingdom (slides)
- “NLP & DBpedia: Literature Review” by Artem Revenko, Semantic Web Company, Austria (slides)
At the same time, the DBpedia Ontology Session provided a platform for the community to discuss implementable criteria to evaluate ontologies, especially the ontology archive DBpedia Archivo. Hereafter you will find all presentations given during this session:
- “Introduction & Motivation” by Sebastian Hellmann, InfAI/DBpedia (slides)
- “Exploiting Semantic Knowledge Graphs to enable data integration and interoperability within the Agrifood sector” by Monika Solanki, Agrimetrics (slides)
- “DBpedia Archivo” by Denis Streitmatter, InfAI/AKSW (slides)
- “FOOPS! An Ontology Pitfall Scanner for the FAIR principles” by Daniel Garijo, UPM (slides)

Diversity of DBpedia – The DBpedia Language Chapters
This year’s DBpedia Day also covered a special chapter session, chaired by Enno Meijers, KB and Dutch DBpedia Language Chapter. Two speakers presented the latest technical and organizational developments of their respective chapters. Furthermore, Johannes Frey showcased the Dutch National Knowledge Graph (DNKG). During the DBpedia Autumn Hackathon 2020 the DBpedia team worked together with a group of Dutch organizations to explore the feasibility of building a DNKG. The knowledge graph was built from a number of authoritative datasets using the DBpedia Databus approach.
Following, you find a list of all presentations of this session:
- “Latest enhancements in the Spanish DBpedia” by Mariano Rico, Technical University of Madrid (UPM) (slides)
- “Creating the Hungarian DBpedia using the Databus” by Andras Micsik, SZTAKI (slides)
- “Dutch National Knowledge Graph pilot” by Johannes Frey, InfAI/DBpedia Association) (slides)
- Discussion about the future of the local DBpedia chapters lead by Enno Meijers
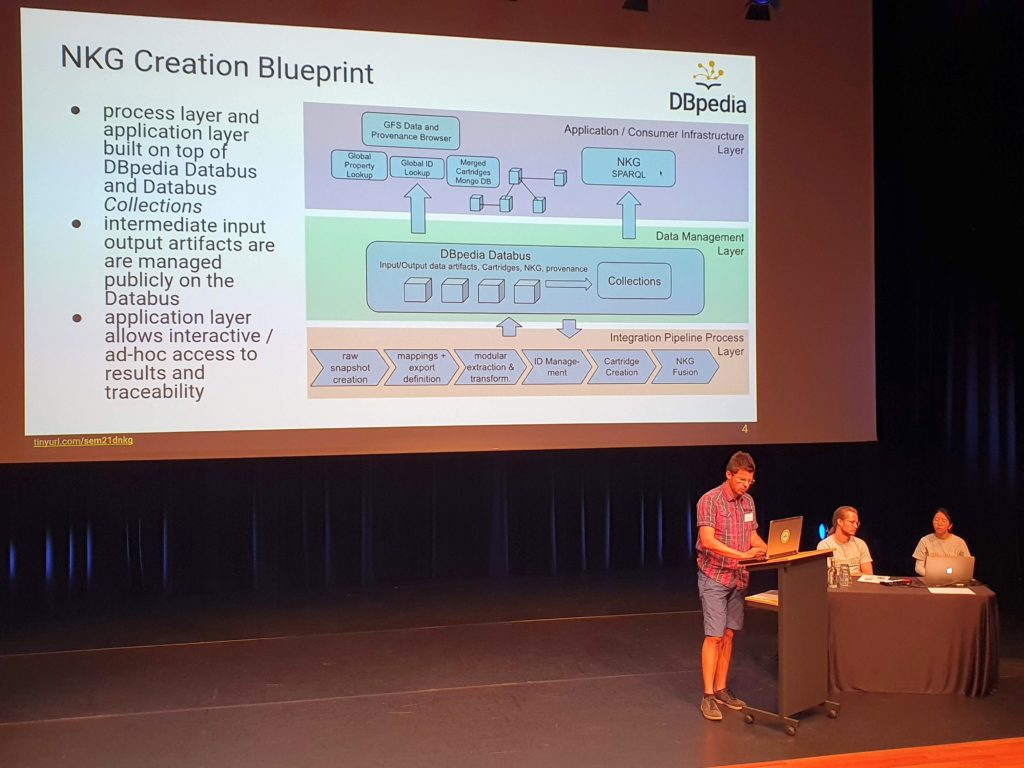
In this DBpedia chapter session we had a closer look at the results of the DNKG pilot. Furthermore, two DBpedia language chapters (Spanish and Hungarian) presented current developments and research results. Closing this session, Enno Meijers led a discussion about the opportunities of the DBpedia Databus for creating local chapters and building (national) knowledge graphs in general.
Summing up, the DBpedia Day at the SEMANTiCS conference brought together more than 100 DBpedia enthusiasts from Europe who engaged in vital discussions about Linked Data, the DBpedia archivo as well as DBpedia use cases and services.
In case you missed the event, all slides are also available on our event page. Further insights, feedback and photos about the event are available on Twitter via #DBpediaDay.
We are now looking forward to more DBpedia meetings in the next year. DBpedia will be part of the Connected Data World taking place online on December 1–3, 2021. We will organize a masterclass.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Julia
on behalf of the DBpedia Association
The post DBpedia Day – Hallo Gemeenschap! appeared first on DBpedia Association.
]]>The post Recap: Google Summer of Code 2021 appeared first on DBpedia Association.
]]>
For the 10th year in a row, we were part of this incredible journey of young ambitious developers who joined us as an open-source organization to work on a Google Summer of Code project.
Each year has brought us new project ideas, many amazing students and mostly great project results that shaped the future of DBpedia.
One of the advantages of Google Summer of Code is, especially in times like these, the chance to work on projects remotely, but still obtain a first deep dive into Open Source projects like us – DBpedia.
Meet our Google Summer of Code students and their projects
Throughout the summer program, our ten finalists worked intensely on their challenging DBpedia projects with great outcomes to show to the public. Projects ranged from extending a neural extraction framework to creating a DBpedia Chatbot as well as creating a dashboard for DBpedia Spotlight. If you want to have deeper insights into our GSoC student’s work you can find their blogs and repos in the following list. Check them out!
- DBpedia Spotlight Dashboard: an integrated statistical information tool from the Wikipedia dumps and the DBpedia Extraction Framework artifacts
- Modular DBpedia Chatbot
- Social Knowledge Graph: Employing SNA measures to Knowledge Graph
- Neural QA Model for DBPedia
- Lifecycle Management of DBpedia Neural QA Models
- Towards a neural extraction framework
- User Centric Knowledge Engineering and Data Visualization
- Web app to generate RDF from DBpedia abstracts
- DBpedia Live Neural Question Answering Chatbot
- Update DBpedia Sparql for newly updated wiki resources and specifically related to pandemic, healthcare, and heath AI fields
Thanks to mentors
Thanks to all our mentors around the world for joining us in this endeavour, for mentoring with kindness and technical expertise. A huge shout out to those who have been by our side for so many years in a row. Many thanks to Tommaso Soru, Beyza Yaman, Diego Moussalem, Ricardo Usbeck, Edgard Marx, Marianno Rico, Thiago Castro Ferreira, Luca Virgili, Ram G Athreya, as well as Sebastian Hellmann, Nausheen Fatma, Said P. Martagon, Krishanu Konar, Zheyuan Bai, Julio Hernandez, Anand Panchbhai, and Jan Forberg. We would also like to thank Andreas Both, Aleksandr Perevalov, Lahiru Hinguruduwa, Marvin Hofer, Maribel Angelica Marin Castro, and Alex Winter, who were mentors for the first time this year. Thank you all again for spending over 3.5+ months working with this year’s GSoC students and helping them become better open source contributors!
Mentor Summit
During the previous years you might have noticed that we always organized a little lottery to decide which mentor or organization admin can join the annual GSoC mentor summit. As this year’s event will be held online, space is open to all organization admins and mentors alike. The GSoC Virtual Mentor Summit takes place on November 4, 2021 and this year we hope all our mentors will find the time to join and exchange with fellow mentors from around dozens of open source projects.
After GSoC is before the next GSoC
We can not wait for the 2022 edition. Likewise, if you are an ambitious student who is interested in open source development and working with DBpedia you are more than welcome to either contribute your own project idea or apply for project ideas we offer starting in early 2022. If you would like to know where previous mentors and students are now working, please read our last GSoC blog post.
In case you like to mentor a project do not hesitate to also get in touch with us via dbpedia@infai.org.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Julia
on behalf of the DBpedia Association
The post Recap: Google Summer of Code 2021 appeared first on DBpedia Association.
]]>The post DBpedia Archivo: 1 Year Retrospective appeared first on DBpedia Association.
]]>September 9th, 2021 at 1pm CEST: In particular, we would like to invite you to the DBpedia Ontology session at the DBpedia Day at SEMANTiCS 2021 to discuss the future roadmap for Archivo as a Unified Semantic Ontology Space (USOS) and what the role of the DBpedia Ontology will be in the Semantic Web.
Session Topics
The session will host impulse talks with ample room for discussion. For the first time in the history of the Semantic Web, Archivo offers the possibility to create a Unified Semantic Ontology Space (USOS), a holistic view over all available ontologies. Instead of soft and fuzzy principles such as FAIR, we will discuss hard, implementable criteria to evaluate ontologies in preparation of a well-defined, measurable standard, which will ultimately yield better and reliable ontologies for industrial applications. Another topic is the central collaboration on links and mappings between ontologies to create a more dense and well-connected web of ontologies. Join the discussion and register here.
Successes and Highlights
An Exhaustive Ontology Archive
We implemented 5 discovery mechanisms that run each week. These mechanisms have proven effective to develop Archivo into one of the most exhaustive ontology archives. As of today, Archivo provides an alternative, persistent download location for 1407 ontologies. Growth has not reached a plateau, yet and it is steadily growing at a pace of 12.6 ontologies per week (6 month average).
Community Adoption
While 1246 ontologies were automatically discovered, we also received 159 user submission (i.e. adding the Ontology URL at https://archivo.dbpedia.org/add). Archivo is also serving 90 ontology downloads on an average day (plus 640 daily downloads from major bots) and will soon provide popularity ratings. The archive can be downloaded as a whole. Note that we also keep some ontologies that are no longer available under their original URL such as: GEORSS (info, download) to allow stable operation of the Semantic Web.
Ontology Accessibility
Archivo uses all kinds of cunning tricks to find, access and persist ontologies. Our crawlers and parsers have matured over the last year and – although we might have overlooked something – we are quite certain that the following statement holds: “If DBpedia Archivo can not process an ontology, the ontology is not retrievable or parseable, which will negatively impact all further applications”. On the other hand, if Archivo manages to access and parse the ontology, it will be persisted for future generations (following a fair use / no abuse policy regarding size restrictions).
Ontology Quality vs. Coverage
Besides accessibility, Archivo evaluates availability and conformity of license statements as well as consistency as a minimal baseline to assign the 4 Archivo stars. On August 16th, 2021, we can report that the web of ontology reached above 2 stars on average with 303 ★★★★, 246 ★★★☆, 18 ★★☆☆ and 836 ★☆☆☆ ontologies. Two weeks later the average fell to 1.999 stars as 4 more ontologies were discovered. We see it as a challenge for Archivo to likewise improve the orthogonal goals of exhaustive coverage as well as high quality ontologies. We believe, however, that the system is able to accommodate both over time.
Versioning
Ontologies are checked every 8 hours for changes. So far Archivo has archived 3713 for the 1407 ontologies. Ontology practitioners are now able to code applications to specific archived ontology versions and need not fear that major ontological changes are published under the same URL, breaking SPARQL queries and applications.
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Sebastian Hellmann
on behalf of the DBpedia Association
The post DBpedia Archivo: 1 Year Retrospective appeared first on DBpedia Association.
]]>