The post Meet the DBpedia Chatbot appeared first on DBpedia Association.
]]>This year’s GSoC is slowly coming to an end with final evaluations already being submitted. In order to bridge the waiting time until final results are published, we like to draw your attention to a former project and great tool that was developed during last years’ GSoC.
Meet the DBpedia Chatbot. 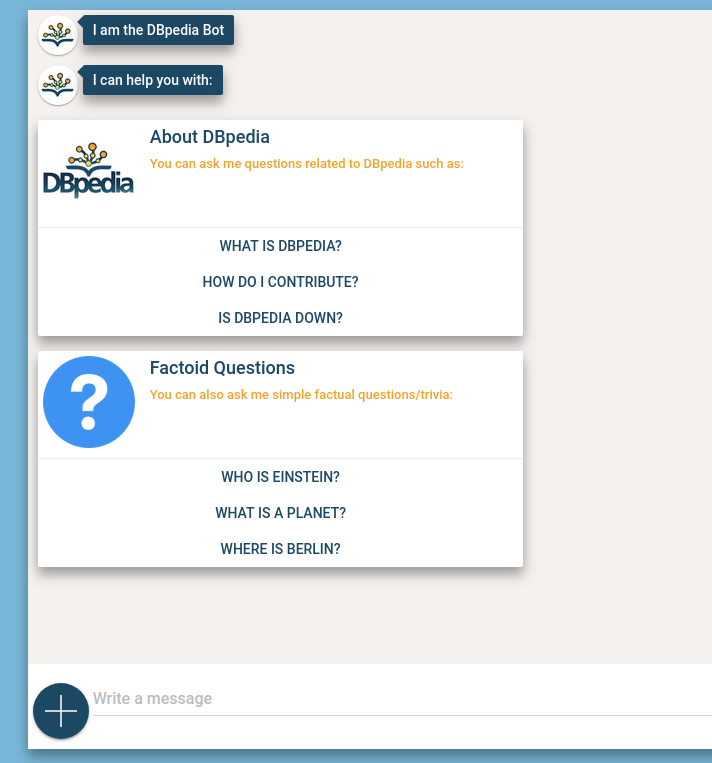
DBpedia Chatbot is a conversational Chatbot for DBpedia which is accessible through the following platforms:
- A Web Interface
- Slack
- Facebook Messenger
Main Purpose
The bot is capable of responding to users in the form of simple short text messages or through more elaborate interactive messages. Users can communicate or respond to the bot through text and also through interactions (such as clicking on buttons/links). There are 4 main purposes for the bot. They are:
- Answering factual questions
- Answering questions related to DBpedia
- Expose the research work being done in DBpedia as product features
- Casual conversation/banter
Question Types
The bot tries to answer text-based questions of the following types:
Natural Language Questions
- Give me the capital of Germany
- Who is Obama?
Location Information
- Where is the Eiffel Tower?
- Where is France’s capital?
Service Checks
Users can ask the bot to check if vital DBpedia services are operational.
- Is DBpedia down?
- Is lookup online?
Language Chapters
Users can ask basic information about specific DBpedia local chapters.
- DBpedia Arabic
- German DBpedia
Templates
These are predominantly questions related to DBpedia for which the bot provides predefined templatized answers. Some examples include:
- What is DBpedia?
- How can I contribute?
- Where can I find the mapping tool?
Banter
Messages which are casual in nature fall under this category. For example:
- Hi
- What is your name?
if you like to have a closer look at the internal processes and how the chatbot was developed, check out the DBpedia GitHub pages.
DBpedia Chatbot was published on wiki.dbpedia.org and is one of many other projects and applications featuring DBpedia.
Powered by WPeMatico
In case you want your DBpedia based tool or demo to publish on our website just follow the link and submit your information, we will do the rest.
Yours
DBpedia Association
The post Meet the DBpedia Chatbot appeared first on DBpedia Association.
]]>The post Meeting with the US-DBpedians – A Wrap-Up appeared first on DBpedia Association.
]]>
Main Event
First and foremost, we would like to thank Apple for the warm welcome and the hosting of the event.
After a Meet & Greet with refreshments, Taylor Rhyne, Eng. Product Manager at Apple, and Pablo N. Mendes, Researcher at Apple and chair of the DBpedia Community Committee, opened the main event with a short introduction setting the tone for the following 2 hours.
The main event attracted attendees with eleven invited talks from major companies of the Bay Area actively using DBpedia or interested in knowledge graphs in general such as Diffbot, IBM, Wikimedia, NTENT, Nuance, Volley and Stardog Union.

Tommaso Soru (University of Leipzig), DBpedia mentor in our Google Summer of Code (GSoC) projects, opened the invited talks session with the updates from the DBpedia developer community. This year, DBpedia participated in the GSoC 2017 program with 7 different projects including “First Chatbot for DBpedia”, which was selected as Best DBpedia GSoC Project 2017. His presentation is available here.
DBpedia likes to thank the following poeple for organizinga nd hosting our Community Meeting in Cupertino, California.
- Pablo N. Mendes (host, program chair), Apple Inc.
- Taylor Rhyne (host), Apple Inc.
- Magnus Knuth, AKSW/KILT
- Filipe Mesquita, diffbot
- Dimitris Kontokostas, DBpedia Chapter Coordinator
- Sebastian Hellmann, AKSW/KILT, DBpedia Association
- Anna Lisa Gentile (IBM Research) and Samuel Goto (Google)
Further Acknowledgments
| Apple Inc. | For sponsoring catering and hosting our meetup on their campus. |
| Google Summer of Code 2017 | Amazing program and the reason some of our core DBpedia devs are visiting California |
| ALIGNED – Software and Data Engineering | For funding the development of DBpedia as a project use-case and covering part of the travel cost |
| Institute for Applied Informatics | For supporting the DBpedia Association |
| OpenLink Software | For continuous hosting of the main DBpedia Endpoint |
Invited Talks- A Short Recap
Filipe Mesquita (Diffbot) introduced the new DBpedia NLP Department, born from a recent partnership between our organization and the California based company, which aims at creating the most accurate and comprehensive database of human knowledge. His presentation is available here. Dan Gruhl (IBM Research) held a presentation about the in-house development of an omnilingual ontology and how DBpedia data supported this

endeavor. Stas Malyshev representative for Dario Taraborelli (both Wikimedia Foundation) presented the current state of the structured data initiatives at Wikidata and the query capabilities for Wikidata. Their slides are available here and here. Ricardo Baeza-Yates (NTENT) gave a short talk on mobile semantic search.
The second part of the event saw Peter F. Patel-Schneider (Nuance) holding a presentation with the title “DBpedia from the Fringe” giving some insights on how DBpedia could be further improved. Shortly after, Sebastian Hellmann, Executive Director of the DBpedia Association, walked the stage and presented the state of the art of the association, including achievements and future goals. Sanjay Krishnan (U.C. Berkeley) talked about the link between AlphaGo and data cleansing. You can find his slides here. Bill Andersen (Volley.com) argued for the use of extremely precise and fine-grained approaches to deal with small data. His presentation is available here. Finally, Michael Grove (Stardog Union) stressed on the view of knowledge graphs as knowledge toolkits backed by a graph data model.

The event concluded with refreshments, snacks and drinks served in the atrium allowing to talk about the presented topics, discuss the latest developments in the field of knowledge graphs and network between all participants. In the end, this closing session was way longer than had been planned.
GSoC Mentor Summit
Shortly after the CA Community Meeting, our DBpedia mentors Tommaso Soru and Magnus Knuth participated at the Google Summer of Code Mentor Summit held in Sunnyvale California. During free sessions hosted by mentors of diverse open source organizations, Tommaso and Magnus presented selected projects during their lightning talks. Beyond open source, open data topics have been targeted in multiple sessions, as this is not only relevant for research, but there is also a strong need in software projects. The meetings paved the way for new collaborations in various areas, e.g. the field of question answering over the DBpedia knowledge corpus, in particular the use of Neural SPARQL Machines for the translation of natural language into structured queries. We expect that this hot deep-learning topic will be featured in the next edition of GSoC projects. Overall, it has been a great experience to meet so many open source fellows from all over the world.
Upcoming events
After the event is before another ….
Connected Data London, November 16th, 2017.
Sebastian Hellmann, executive director of the DBpedia Association will present Data Quality and Data Usage in a large-scale Multilingual Knowledge Graph during the content track at the Connected Data in London. He will also join the panelists in the late afternoon panel discussion about Linked Open Data: Is it failing or just getting out of the blocks? Feel free to join the event and support DBpedia.
A message for all DBpedia enthusiasts – our next Community Meeting
Currently we are planning our next Community Meeting and would like to invite DBpedia enthusiasts and chapters who like to host a meeting to send us their ideas to dbpedia@infai.org. The meeting is scheduled for the beginning of 2018. Any suggestions regarding place, time, program and topics are welcome!
Check our website for further updates, follow us on #twitter or subscribe to our newsletter.
We will keep you posted
Your DBpedia Association
The post Meeting with the US-DBpedians – A Wrap-Up appeared first on DBpedia Association.
]]>The post GSoC 2017 – Recap and Results appeared first on DBpedia Association.
]]>Marco Fossati, Dimitris Kontokostas, Tommaso Soru, Domenico Potena, Emanuele Storti , anastasia Dimiou, Wouter Maroy, Peng Xu, Sandro Coelho and Ricardo Usbeck, members of the DBpedia Community, did a great job in mentoring 7 students from around the world. All of the students enjoyed the experiences made during the program and will hopefully continue to contribute to DBpedia in the future.
“GSoC is the perfect opportunity to learn from experts, get to know new communities, design principles and work flows.” (Ram G Athreya)”
Now, we would like to take that opportunity to give you a little recap of the projects mentored by DBpedia members during the past months. Just click below for more details .
[expander_maker id=”1″ more=”Read more” less=”Read less”]DBpedia Mappings Front-End Administration by Ismael Rodriguez
The goal of the project was to create a front-end application that provides a user-friendly interface so the DBPedia community can easily view, create and administrate DBpedia mapping rules using RML. The developed system includes user administration features, help posts, Github mappings synchronization, and rich RML related features such as syntax highlighting, RML code generation from templates, RML validation, extraction and statistics. Part of these features are possible thanks to the interaction with the DBPedia Extraction Framework. In the end, all the functionalities and goals that were required have been developed, with many functional tests and the approval of the DBpedia community. The system is ready for production deployment. For further information, please visit the project blog. Mentors: Anastasia Dimou and Wouter Maroy (Ghent University), Dimitris Kontokostas (GeoPhy HQ).
Chatbot for DBpedia by Ram G Athreya
DBpedia Chatbot is a conversational chatbot for DBpedia which is accessible through the following platforms: a Web Interface, Slack and Facebook Messenger.
The bot is capable of responding to users in the form of simple short text messages or through more elaborate interactive messages. Users can communicate or respond to the bot through text and also through interactions (such as clicking on buttons/links). The bot tries to answer text based questions of the following types: natural language questions, location information, service checks, language chapters, templates and banter. For more information, please follow the link to the project site. Mentor: Ricardo Usbeck (AKSW).
Knowledge Base Embeddings for DBpedia by Nausheen Fatma
Knowledge base embeddings has been an active area of research. In recent years a lot of research work such as TransE, TransR, RESCAL, SSP, etc. has been done to get knowledge base embeddings. However none of these approaches have used DBpedia to validate their approach. In this project, I want to achieve the following tasks: i) Run the existing techniques for KB embeddings for standard datasets. ii) Create an equivalent standard dataset from DBpedia for evaluations. iii) Evaluate across domains. iv) Compare and Analyse the performance and consistency of various approaches for DBpedia dataset along with other standard datasets. v) Report any challenges that may come across implementing the approaches for DBpedia. For more information, please follow the links to her project blog and GitHub-repository. Mentors: Tommaso Soru (AKSW) and Sandro Coelho (KILT).
Knowledge Base Embeddings for DBpedia by Akshay Jagatap
The project defined embeddings to represent classes, instances and properties by implementing Random Vector Accumulators with additional features in order to better encode the semantic information held by the Wikipedia corpus and DBpedia graphs. To test the quality of embeddings generated by the RVA, lexical memory vectors of locations were generated and tested on a modified subset of the Google Analogies Test Set. Check out further information via Akshay’s GitHub-repo. Mentors: Tommaso Soru (AKSW) and Xu Peng (University of Alberta).
The Table Extractor by Luca Vergili
Wikipedia is full of data hidden in tables. The aim of this project was to explore the possibilities of exploiting all the data represented with the appearance of tables in Wiki pages, in order to populate the different chapters of DBpedia through new data of interest. The Table Extractor has to be the engine of this data “revolution”: it would achieve the final purpose of extracting the semi structured data from all those tables now scattered in most of the Wiki pages. In this page you can observe dataset (english and italian) extracted using table extractor . Furthermore you can read log file created in order to see all operations made up for creating RDF triples. I recommend to also see this page, that contains the idea behind the project and an example of result extracted from log files and .ttl dataset. For more details see Luca’s Git-Hub repository. Mentors: Domenico Potena and Emanuele Storti (Università Politecnica delle Marche).
Unsupervised Learning of DBpedia Taxonomy by Shashank Motepalli
Wikipedia represents a comprehensive cross-domain source of knowledge with millions of contributors. The DBpedia project tries to extract structured information from Wikipedia and transform it into RDF.
The main classification system of DBpedia depends on human curation, which causes it to lack coverage, resulting in a large amount of untyped resources. DBTax provides an unsupervised approach that automatically learns a taxonomy from the Wikipedia category system and extensively assigns types to DBpedia entities, through the combination of several NLP and interdisciplinary techniques. It provides a robust backbone for DBpedia knowledge and has the benefit of being easy to understand for end users. details about his work and his code can e found on the projects site. Mentors: Marco Fossati (Università degli Studi di Trento) and Dimitris Kontokostas (GeoPhy HQ).
The Wikipedia List-Extractor by Krishanu Konar
This project aimed to augment upon the already existing list-extractor project by Federica in GSoC 2016. The project focused on the extraction of relevant but hidden data which lies inside lists in Wikipedia pages. Wikipedia, being the world’s largest encyclopedia, has humongous amount of information present in form of text. While key facts and figures are encapsulated in the resource’s infobox, and some detailed statistics are present in the form of tables, but there’s also a lot of data present in form of lists which are quite unstructured and hence its difficult to form into a semantic relationship. The main objective of the project was to create a tool that can extract information from Wikipedia lists and form appropriate RDF triplets that can be inserted in the DBpedia dataset. Fore details on the code and about the project check Krishanu’s blog and GitHub-repository. Mentors: Marco Fossati (Università degli Studi di Trento), Domenico Potena and Emanuele Storti (Università Politecnica delle Marche). [/expander_maker]
We are regularly growing our community through GSoC and can deliver more and more opportunities to you. Ideas and applications for the next edition of GSoC are very much welcome. Just contact us via email or check our website for details.
Again, DBpedia is planning to be a vital part of the GSoC Mentor Summit, from October 13th -15th, at the Google Campus in Sunnyvale California. This summit is a way to say thank you to the mentors for the great job they did during the program. Moreover it is a platform to discuss what can be done to improve GSoC and how to keep students involved in their communities post-GSoC.
And there is more good news to tell. DBpedia wants to meet up with the US community during the 11th DBpedia Community Meeting in California. We are currently working on the program and keep you posted as soon as registration is open.
So, stay tuned and check Twitter, Facebook and the Website or subscribe to our Newsletter for latest news and updates.
See you soon!
Yours,
DBpedia Association
The post GSoC 2017 – Recap and Results appeared first on DBpedia Association.
]]>