The post Vítejte v Praze! appeared first on DBpedia Association.
]]>First and foremost, we would like to thank Jirka Kosek (University of Economics, Prague), Milan Dojchinovski (AKSW/KILT, Czech Technical University in Prague), Tomáš Kliegr (KIZI/University of Economics, Prague) and, the XML Prague conference for co-hosting and support the event.
Opening the DBpedia community meetup
 The Czech DBpedia community and the DBpedia Databus were in the focus of this meetup. Therefore, we invited local data scientists as well as DBpedia enthusiasts to discuss the state-of-the-art of the DBpedia databus. Sebastian Hellmann (AKSW/KILT) opened the meeting with an introduction to DBpedia and the DBpedia Databus. Following, Marvin Hofer explained how to use the DBpedia databus in combination with the Docker technology and, Johannes Frey (AKSW/KILT) presented the methods behind the DBpedia’s Data Fusion and Global ID Management.
The Czech DBpedia community and the DBpedia Databus were in the focus of this meetup. Therefore, we invited local data scientists as well as DBpedia enthusiasts to discuss the state-of-the-art of the DBpedia databus. Sebastian Hellmann (AKSW/KILT) opened the meeting with an introduction to DBpedia and the DBpedia Databus. Following, Marvin Hofer explained how to use the DBpedia databus in combination with the Docker technology and, Johannes Frey (AKSW/KILT) presented the methods behind the DBpedia’s Data Fusion and Global ID Management.
Showcase Session
Marek Dudáš (KIZI/UEP) started the DBpedia Showcase Session with a presentation on “Concept Maps with the help of DBpedia”, where he showed the audience how to create a “concept map” with the ContextMinds application. Furthermore, Tomáš Kliegr (KIZI/UEP) presented “Explainable Machine Learning and Knowledge Graphs”. He explained his contribution to a rule-based classifier for business use cases. Two other showcases followed: Václav Zeman (KIZI/UEP), who presented “RdfRules: Rule Mining from DBpedia” and Denis Streitmatter (AKSW/KILT), who demonstrated the “DBpedia API”.

Closing this Session, Miroslav Blasko (CTU, Prague) gave a presentation on “Ontology-based Dataset Exploration”. He explained a taxonomy developed for dataset description. Additionally, he presented several use cases that have the main goal of improving content-based descriptors.
Summing up, the DBpedia meetup in Prague brought together more than 50 DBpedia enthusiasts from all over Europe. They engaged in vital discussions about Linked Data, the DBpedia databus, as well as DBpedia use cases and services.
In case you missed the event, all slides and presentations are available on our website. Further insights feedback, and photos about the event can be found on Twitter via #DBpediaPrague.
We are currently looking forward to the next DBpedia Community Meeting, on May 23rd, 2019 in Leipzig, Germany. This meeting is co-located with the Language, Data and Knowledge (LDK) conference. Stay tuned and check Twitter, Facebook and the website or subscribe to our newsletter for the latest news and updates.
Your DBpedia Association
The post Vítejte v Praze! appeared first on DBpedia Association.
]]>The post Call for Participation: DBpedia meetup @ XML Prague appeared first on DBpedia Association.
]]>Highlights
– Intro: DBpedia: Global and Unified Access to Knowledge (Graphs)
– DBpedia Databus presentation
– DBpedia Showcase Session
Quick Facts
– Web URL: https://wiki.dbpedia.org/meetings/Prague2019
– When: February 7th, 2019
– Where: University of Economics, nam. W. Churchilla 4, 130 67 Prague 3, Czech Republic
Schedule
– Please check the schedule for the upcoming DBpedia meetup here: https://wiki.dbpedia.org/meetings/Prague2019
Tickets
– Attending the DBpedia Community Meetup costs €40. DBpedia members get free admission, please contact your nearest DBpedia chapter or the DBpedia Association for a promotion code.
– You need to buy a ticket. Please check all details here: http://www.xmlprague.cz/conference-registration/
Sponsors and Acknowledgements
– XML conference Prague (http://www.xmlprague.cz/)
– Institute for Applied Informatics (http://infai.org/en/AboutInfAI)
– OpenLink Software (http://www.openlinksw.com/)
Organisation
-Milan Dojčinovski, AKSW/KILT
– Julia Holze, DBpedia Association
– Sebastian Hellmann, AKSW/KILT, DBpedia Association
– Tomáš Kliegr, KIZI/University of Economics, Prague
Tell us what cool things you do with DBpedia. If you would like to give a talk at the DBpedia meetup, please get in contact with the DBpedia Association.
We are looking forward to meeting you in Prague!
For latest news and updates check Twitter, Facebook and our Website or subscribe to our newsletter.
Your DBpedia Association
The post Call for Participation: DBpedia meetup @ XML Prague appeared first on DBpedia Association.
]]>The post Who are these DBpedia users ? …(and why ? ) appeared first on DBpedia Association.
]]>Who uses DBpedia anyway?…
This question started a research project for Frank Walraven, an Information Sciences Master student at Vrije Universiteit Amsterdam (VUA). The question came up during one of the meetings of the Dutch DBpedia chapter, of which VUA is a member.
If DBpedia users and their usage are better understood, this can lead to better servicing of those Dbpedia users by, for example, prioritizing the enrichment or improvement of specific sections of DBpedia. Characterizing use(r)s of a Linked Open Dataset is an inherently challenging task because in an open web world it is difficult to tell who is accessing your digital resources.
Frank conducted his MSc project research at the Dutch National Library and used a hybrid approach utilizing both, a data-driven method based on user log analysis and a short survey to get to know the users of the dataset.

As a scope, Frank selected just the Dutch DBpedia dataset. For the data-driven part of the method, Frank used a complete user log of HTTP requests on the Dutch DBpedia. This log file consisted of over 4.5 Million entries and logged both URI lookups and SPARQL endpoint requests. For this research, he only included a subset of the URI lookups.
Analysis of IP- Addresses od DBpedia Users
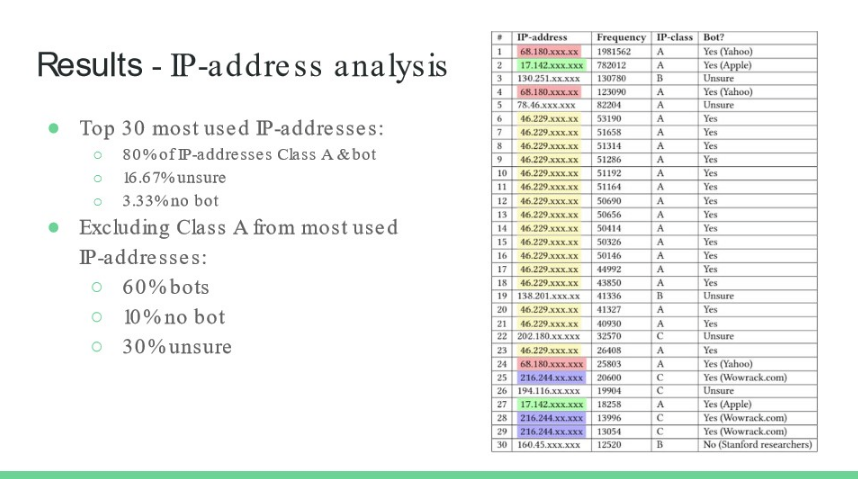
As a first analysis step, the requests’ origins IPs were categorized. Five classes can be identified (A-E), with the vast majority of IP addresses being in class “A”: Very large networks and bots. Most of the IP addresses in these lists could be traced back to search engine indexing bots such as those from Yahoo or Google. In classes B-F, Frank manually traced the top 30 most encountered IP-addresses. He concluded that even there 60% of the requests came from bots, 10% definitely not from bots, with 30% remaining unclear.

Step II – Identification of Page Requests
The second analysis step in the data-driven method consisted of identifying what types of pages were most requested. To cluster the thousands of DBpedia URI request, Frank retrieved the ‘categories’ of the pages. These categories are extracted from Wikipedia category links. An example is the “Android_TV” resource, which has two categories: “Google” and “Android_(operating_system)”. Following skos:broader links, a ‘level 2 category’ could also be found to aggregate to an even higher level of abstraction. As not all resources have such categories, this does not give a complete image, but it does provide some ideas on the most popular categories of items requested. After normalizing for categories with large amounts of incoming links, for example, the category “non-endangered animal”, the most popular categories where
- 1. Domestic & International movies,
- 2. Music,
- 3. Sports,
- 4. Dutch & International municipality information and
- 5. Books.
Survey
Additionally, Frank set up a user survey to corroborate this evidence. The survey contained questions about the how and why of the respondents use of the Dutch DBpedia, including the categories they were most interested in.
The survey was distributed using the Dutch DBpedia website and via Twitter. However, the endeavour only attracted 5 respondents. This illustrates the difficulty of the problem that users of the DBpedia resource are not necessarily easily reachable through communication channels. The five respondents were all quite closely related to the chapter but the results were interesting nonetheless. Most of the DBpedia users used the DBpedia SPARQL endpoint. The full results of the survey can be found through Frank’s thesis, but in terms of corroboration, the survey revealed that four out of the five categories found in the data-driven method were also identified in the top five results from the survey. The fifth one identified in the survey was ‘geography’, which could be matched to the fifth from the data-driven method.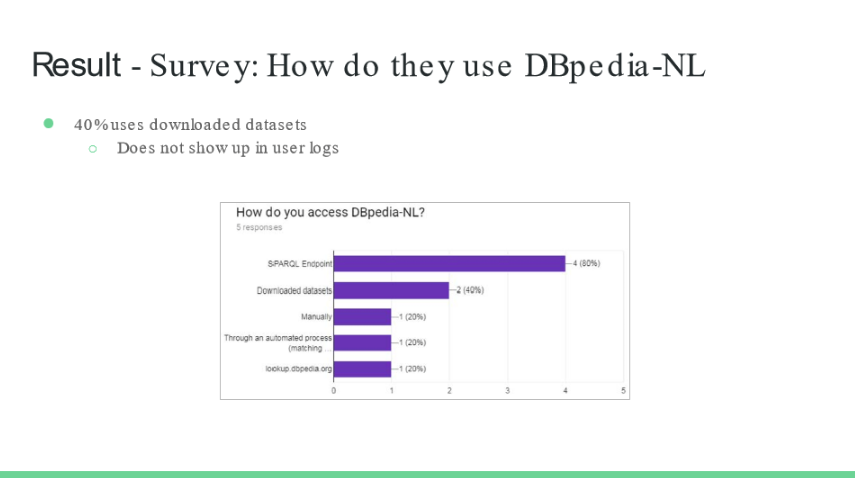
Conclusion
Frank’s research shows that it remains a challenging problem, using a combination of data-driven and user-driven method. Yet, it is indeed possible to get an indication into the most-used categories on DBpedia. Within the Dutch DBpedia Chapter, we are currently considering follow-up research questions based on Frank’s research. For further information about the work of the Dutch DBpedia chapter, please visit their website.
A big thanks to the Dutch DBpedia Chapter for supervising this research and providing insights via this post.
Yours
DBpedia Association
The post Who are these DBpedia users ? …(and why ? ) appeared first on DBpedia Association.
]]>The post DBpedia Chapters – Survey Evaluation – Episode One appeared first on DBpedia Association.
]]>The DBpedia community currently comprises more than 20 language chapters, ranging from Basque, Japanese to Portuguese and Ukrainian. Managing such a variety of chapters is a huge challenge for the DBpedia Association because individual requirements are as diverse as the different languages the chapters represent. There are chapters that started out back in 2012 such as DBpediaNL. Others like the Catalan chapter are brand new and have different haves and needs.
So, in order to optimize chapter development, we aim to formalize an official DBpedia Chapter Consortium. It permits a close dialogue with the chapters in order to address all relevant matters regarding communication, organization as well as technical issues. We want to provide the community with the best basis to set up new chapters and to maintain or develop the existing ones.
Our main targets for this are to:
- improve general chapter organization,
- unite all DBpedia chapters with central DBpedia,
- promote better communication and understanding and,
- create synergies for further developments and make easier the access to information about which is done by all DBpedia bodies
As a first step, we needed to collect information about the current state of things. Hence, we conducted two surveys to collect the necessary information. One was directed at chapter leads and the other one at technical heads.
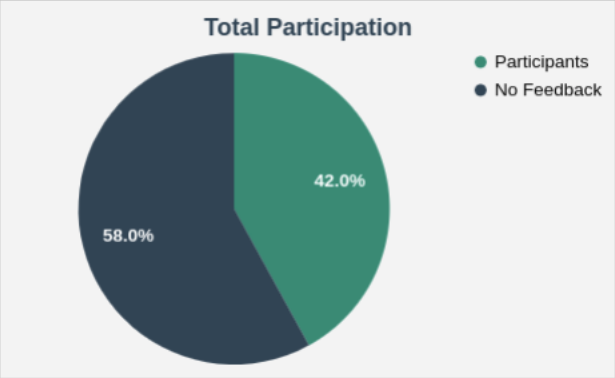 In this blog-post, we like to present you the results of the survey conducted with chapter leads. It addressed matters of communication and organizational relevance. Unfortunately, only nine out of 21 chapters participated, so the respective outcome of the survey speaks only for roughly 42% of all DBpedia chapters.
In this blog-post, we like to present you the results of the survey conducted with chapter leads. It addressed matters of communication and organizational relevance. Unfortunately, only nine out of 21 chapters participated, so the respective outcome of the survey speaks only for roughly 42% of all DBpedia chapters.
Chapter-Survey – Episode One
Most chapters have very little personnel committed to the work done for the chapter, due to different reasons. 66 % of the chapters have only one till four people being involved in the core work. Only one chapter has about ten people working on it.
Overall, the chapters use various marketing channels for promotion, visibility and outreach. The website as well as event participation, Twitter and Facebook are among the most favourite channels they use.
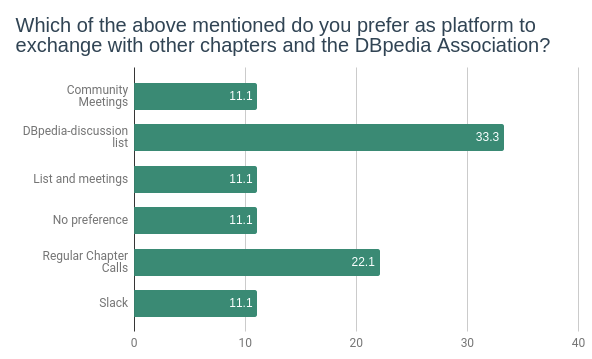
The following chart shows how chapters currently communicate organizational and communication issues in their respective chapter and to the DBpedia Association.
The second one explicit that ⅓ of the chapters favour an exchange among chapters and with the DBpedia Association via the discussion mailing list as well as regular chapter calls.
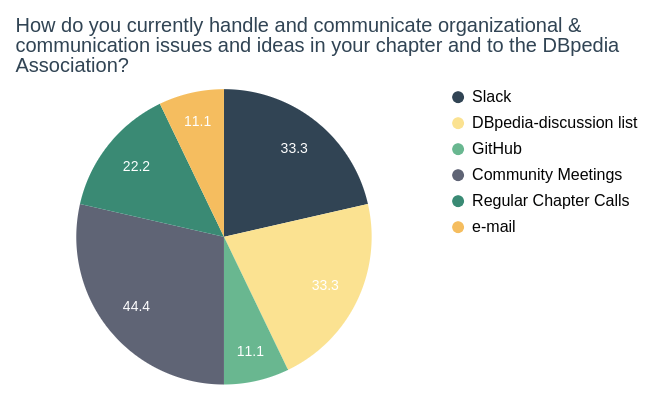
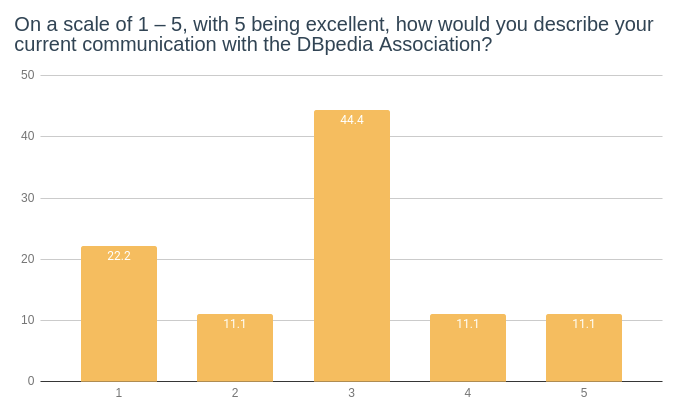 The survey results show that 66,6% of the chapters currently do not consider their current mode of communication efficient enough. They think that their communication with the DBpedia Association should improve.
The survey results show that 66,6% of the chapters currently do not consider their current mode of communication efficient enough. They think that their communication with the DBpedia Association should improve.
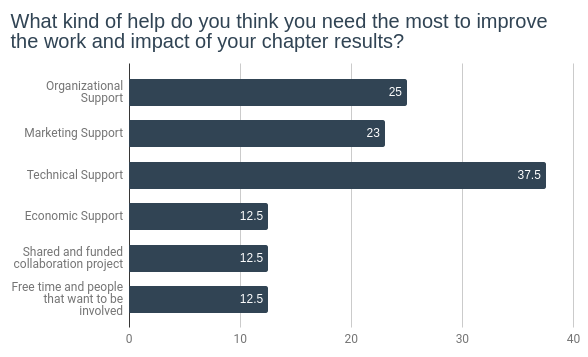
As pointed out before, most chapters only have little personnel resources. It is no wonder that most of them need help to improve the work and impact of chapter results. The following chart shows the kind of support chapters require to improve their overall work, organization and communication. Most noteworthy, technical, marketing and organization support are hereby the top three aspects the chapters need help with.
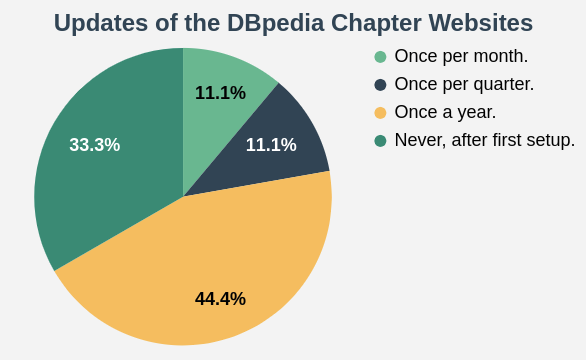
The good news is all of the chapters maintain a DBpedia Website. However, the frequency of updates varies among them. See the chart on the right.
Earlier this year, we announced that we like to align all chapter websites with the main DBpedia website. That includes a common structure and a corporate design, similar to the main one. Above all, this is important for the overal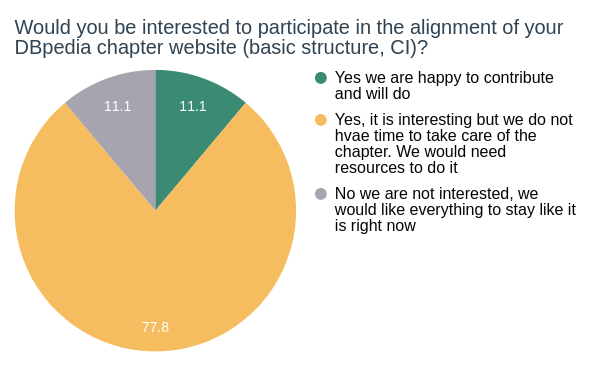 l image and recognition factor of DBpedia in the tech community. With respect to that, we inquired whether chapters would like to participate in an alignment of the websites or not.
l image and recognition factor of DBpedia in the tech community. With respect to that, we inquired whether chapters would like to participate in an alignment of the websites or not.
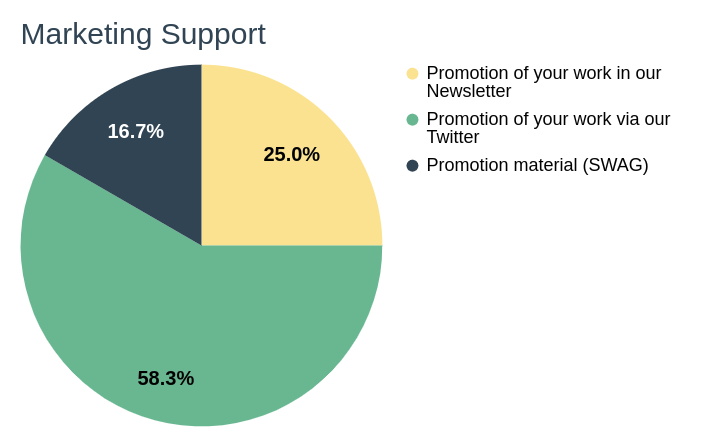 With respect to marketing support, the chapters require from the Association, more than 50% of the chapters like to be frequently promoted via the main DBpedia twitter channel.
With respect to marketing support, the chapters require from the Association, more than 50% of the chapters like to be frequently promoted via the main DBpedia twitter channel.
Good news: just forward us your news or tag us with @dbpedia and we will share ’em.
Almost there.
Finally, we asked about chapters requirements to improve their work and, the impact of their chapters’ results.
Bottom line
All in all, we are very grateful for your contribution. Those data will help us to develop a strategy to work towards the targets mentioned above. We will now use this data to conceptualize a little program to assist chapters in their organization and marketing endeavours. Furthermore, the information given will also help us to tackle the different issues that arose, implement the necessary support and improve chapter development and chapter visibility.
In episode two, we will delve into the results of the technical survey. Sit tight and follow us on Twitter, Facebook, LinkedIn or subscribe to our newsletter.
Finally, one last remark. If you want to promote news of your chapter or otherwise like to increase its visibility, you are always welcome to:
- forward us the respective information to be promoted via our marketing channels
- use your own Twitter channel and tag your post with @dbpedia, so we can retweet your news.
- always use #dbpediachapters
Looking forward to your news.
Yours
DBpedia Association
The post DBpedia Chapters – Survey Evaluation – Episode One appeared first on DBpedia Association.
]]>