The post DBpedia Live Restart – Getting Things Done appeared first on DBpedia Association.
]]>DBpedia Live is a long term core project of DBpedia that immediately extracts fresh triples from all changed Wikipedia articles. After a long hiatus, fresh and live updated data is available once again, thanks to our former co-worker Lena Schindler whose work we feature in this blog post. Before we dive into Lena’s report, let’s have a look at some general info about DBpedia Live:
Live Enterprise Version
OpenLink Software provides a scalable, dedicated, live Virtuoso instance, built on Lena’s remastering. Kingsley Idehen announced the dedicated business service in our new DBpedia forum. .
On the Databus, we collect publicly shared and business-ready dedicated services in the same place where you can download the data. Databus allows you to download the data, build a service, and offer that service, all in one place. Data up-loaders can also see who builds something with their data
Remastering the DBpedia Live Module
Contribution by Lena Schindler
After developing the DBpedia REST API as part of a student project in 2018, I worked as a student Research Assistant for DBpedia. My task was to analyze and patch severe issues in the DBpedia Live instance. I will shortly describe the purpose of DBpedia Live, the reasons it went out of service, what I did to fix these, and finally, the changes needed to support multi-language abstract extraction.
Overview
The DBpedia Extraction Framework is Scala-based software with numerous features that have evolved around extracting knowledge (as RDF) from Wikis. One part is the DBpedia Live module in the “live-deployed” branch, which is intended to provide a continuously updated version of DBpedia by processing Wikipedia pages on demand, immediately after they have been modified by a user. The backbone of this module is a queue that is filled with recently edited Wikipedia pages, combined with a relational database, called Live Cache, that handles the diff between two consecutive versions of a page. The module that fills the queue, called Feeder, needs some kind of connection to a Wiki instance that reports changes to a Wiki Page. The processing then takes place in four steps:
- A wiki page is taken out of the queue.
- Triples are extracted from the page, with a given set of extractors.
- The new triples from the page are compared to the old triples from the Live Cache.
- The triple sets that have been deleted and added are published as text files, and the Cache is updated.
Background
DBpedia Live has been out of service since May 2018, due to the termination of the Wikimedia RCStream Service, upon which the old DBpedia Live Feeder module relied. This socket-based service provided information about changes to an existing Wikimedia instance and was replaced by the EventStreams service, which runs over a single HTTP connection using chunked transfer encoding, and is following the Server-Sent Event (SSE) protocol. It provides a stream of events, each of which contains information about title, id, language, author, and time of every page edit of all Wikimedia instances.
Fix
Starting in September 2018, my first task was to implement a new Feeder for DBpedia Live that is based on this new Wikimedia EventStreams Service. For the Java world, the Akka framework provides an implementation of a SSE client. Akka is a toolkit developed by Lightbend. It simplifies the construction of concurrent and distributed JVM applications, enabling both Java and Scala access. The Akka SSE client and the Akka Streams module are used in the new EventStreamsFeeder (Akka Helper) to extract and process the data stream. I decided to use Scala instead of Java, because it is a more natural fit to Akka.
After I was able to process events, I had the problem that frequent interruptions in the upstream connection were causing the processing stream to fail. Luckily, Akka provides a fallback mechanism with back-off, similar to the Binary Exponential Backoff of the Ethernet protocol which I could use to restart the stream (called “Graph” in Akka terminology).
Another problem was that in many cases, there were many changes to a page within a short time interval, and if events were processed quickly enough, each change would be processed separately, stressing the Live Instance with unnecessary load. A simple “thread sleep” reduced the number of change-sets being published every hour from thousands to a few hundred.
Multi-language abstracts
The next task was to prepare the Live module for the extraction of abstracts (typically the first paragraph of a page, or the text before the table of contents). The extractors used for this task were re-implemented in 2017. It turned out to be a configuration issue first, and second a candidate for long debugging sessions, fixing issues in the dependencies between the “live” and “core” modules. Then, in order to allow the extraction of abstracts in multiple languages, the “live” module needed many small changes, at places spread across the code-base, and care had to be taken not to slow down the extraction in the single language case, compared to the performance before the change. Deployment was delayed by an issue with the remote management unit of the production server, but was accomplished by May 2019.
Summary
I also collected my knowledge of the Live module in detailed documentation, addressed to developers who want to contribute to the code. This includes an explanation of the architecture as well as installation instructions. After 400 hours of work, DBpedia Live is alive and kicking, and now supports multi-language abstract extraction. Being responsible for many aspects of Software Engineering, like development, documentation, and deployment, I was able to learn a lot about DBpedia and the Semantic Web, hone new skills in database development and administration, and expand my programming experience using Scala and Akka.
“Thanks a lot to the whole DBpedia Team who always provided a warm and supportive environment!”
Thank you Lena, it is people like you who help DBpedia improve and develop further, and help to make data networks a reality.
Follow DBpedia on LinkedIn, Twitter or Facebook and stop by the DBpedia Forum to check out the latest discussions.
Yours DBpedia Association
The post DBpedia Live Restart – Getting Things Done appeared first on DBpedia Association.
]]>The post Meet the DBpedia Chatbot appeared first on DBpedia Association.
]]>This year’s GSoC is slowly coming to an end with final evaluations already being submitted. In order to bridge the waiting time until final results are published, we like to draw your attention to a former project and great tool that was developed during last years’ GSoC.
Meet the DBpedia Chatbot. 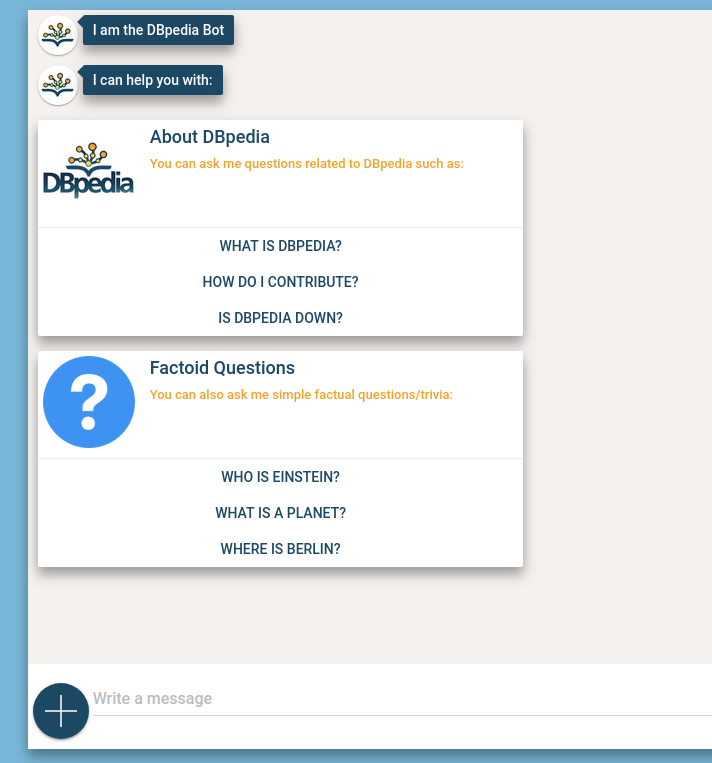
DBpedia Chatbot is a conversational Chatbot for DBpedia which is accessible through the following platforms:
- A Web Interface
- Slack
- Facebook Messenger
Main Purpose
The bot is capable of responding to users in the form of simple short text messages or through more elaborate interactive messages. Users can communicate or respond to the bot through text and also through interactions (such as clicking on buttons/links). There are 4 main purposes for the bot. They are:
- Answering factual questions
- Answering questions related to DBpedia
- Expose the research work being done in DBpedia as product features
- Casual conversation/banter
Question Types
The bot tries to answer text-based questions of the following types:
Natural Language Questions
- Give me the capital of Germany
- Who is Obama?
Location Information
- Where is the Eiffel Tower?
- Where is France’s capital?
Service Checks
Users can ask the bot to check if vital DBpedia services are operational.
- Is DBpedia down?
- Is lookup online?
Language Chapters
Users can ask basic information about specific DBpedia local chapters.
- DBpedia Arabic
- German DBpedia
Templates
These are predominantly questions related to DBpedia for which the bot provides predefined templatized answers. Some examples include:
- What is DBpedia?
- How can I contribute?
- Where can I find the mapping tool?
Banter
Messages which are casual in nature fall under this category. For example:
- Hi
- What is your name?
if you like to have a closer look at the internal processes and how the chatbot was developed, check out the DBpedia GitHub pages.
DBpedia Chatbot was published on wiki.dbpedia.org and is one of many other projects and applications featuring DBpedia.
Powered by WPeMatico
In case you want your DBpedia based tool or demo to publish on our website just follow the link and submit your information, we will do the rest.
Yours
DBpedia Association
The post Meet the DBpedia Chatbot appeared first on DBpedia Association.
]]>The post To the DBpedia Community! appeared first on DBpedia Association.
]]>… that it has already been eleven years since the first DBpedia dataset was released? Eleven years of development, improvements and growth, and now, 13 billion pieces of information are comprised in our last DBpedia release. We want to take this opportunity to send out a big thank you to all contributors, developers, coders, hosters, funders, believers and DBpedia enthusiasts who made that possible. Thank you for your support.
But, apart from our data sets, there is much more DBpedia has been doing., especially during the past year. Think about the success story of Wouter Maroy, a GSoC 2016 student who got the opportunity to do a six weeks internship at our DBpedia office in Leipzig and who is still contributing to DBpedia’s progress.
All in all, 2017 was highly successful and full of exciting events. Remember our 10th DBpedia Community Meeting in Amsterdam featuring an inspiring keynote by Dr. Chris Welty, one of the developers at IBM computer Watson. Our DBpedia meetings are always a great way to bring the community closer together, and to not only meet our DBpedia audience but also new faces. Therefore, we have already started to plan our community meetings for 2018.
We hope to see you in Poznan, Poland, in spring and to meet you during the SEMANTiCS Conference in Vienna, from 10th – 13th of September 2018. Additionally, if everything goes according to plan, we will be mentoring young DBpedia enthusiasts throughout summer in GSoC 2018 and meet the US DBpedia community in autumn this year. Follow us on Twitter or check our Website for the latest News.
And last but not least, this year we plan something special. DBpedia intends to participate in Coding DaVinci – Germany’s first open cultural hackathon, which happens to take place in Leipzig, right around the corner. Aspiring data enthusiast will develop new creative applications from cultural open data. The kick-off is in early April, followed by 9 weeks of cooperative coding. We are eagerly awaiting the start of this event.
We do hope, we will meet you and some new faces during our events this year. The DBpedia Association want to get to know you because DBpedia is a community effort and would not continue to develop, improve and grow without you. Thank you and see you soon…
Subscribe to the DBpedia Newsletter, check our DBpedia Website and follow us on Twitter, Facebook and LinkedIn for latest news.
Your DBpedia Association
The post To the DBpedia Community! appeared first on DBpedia Association.
]]>The post Meeting with the US-DBpedians – A Wrap-Up appeared first on DBpedia Association.
]]>
Main Event
First and foremost, we would like to thank Apple for the warm welcome and the hosting of the event.
After a Meet & Greet with refreshments, Taylor Rhyne, Eng. Product Manager at Apple, and Pablo N. Mendes, Researcher at Apple and chair of the DBpedia Community Committee, opened the main event with a short introduction setting the tone for the following 2 hours.
The main event attracted attendees with eleven invited talks from major companies of the Bay Area actively using DBpedia or interested in knowledge graphs in general such as Diffbot, IBM, Wikimedia, NTENT, Nuance, Volley and Stardog Union.

Tommaso Soru (University of Leipzig), DBpedia mentor in our Google Summer of Code (GSoC) projects, opened the invited talks session with the updates from the DBpedia developer community. This year, DBpedia participated in the GSoC 2017 program with 7 different projects including “First Chatbot for DBpedia”, which was selected as Best DBpedia GSoC Project 2017. His presentation is available here.
DBpedia likes to thank the following poeple for organizinga nd hosting our Community Meeting in Cupertino, California.
- Pablo N. Mendes (host, program chair), Apple Inc.
- Taylor Rhyne (host), Apple Inc.
- Magnus Knuth, AKSW/KILT
- Filipe Mesquita, diffbot
- Dimitris Kontokostas, DBpedia Chapter Coordinator
- Sebastian Hellmann, AKSW/KILT, DBpedia Association
- Anna Lisa Gentile (IBM Research) and Samuel Goto (Google)
Further Acknowledgments
| Apple Inc. | For sponsoring catering and hosting our meetup on their campus. |
| Google Summer of Code 2017 | Amazing program and the reason some of our core DBpedia devs are visiting California |
| ALIGNED – Software and Data Engineering | For funding the development of DBpedia as a project use-case and covering part of the travel cost |
| Institute for Applied Informatics | For supporting the DBpedia Association |
| OpenLink Software | For continuous hosting of the main DBpedia Endpoint |
Invited Talks- A Short Recap
Filipe Mesquita (Diffbot) introduced the new DBpedia NLP Department, born from a recent partnership between our organization and the California based company, which aims at creating the most accurate and comprehensive database of human knowledge. His presentation is available here. Dan Gruhl (IBM Research) held a presentation about the in-house development of an omnilingual ontology and how DBpedia data supported this

endeavor. Stas Malyshev representative for Dario Taraborelli (both Wikimedia Foundation) presented the current state of the structured data initiatives at Wikidata and the query capabilities for Wikidata. Their slides are available here and here. Ricardo Baeza-Yates (NTENT) gave a short talk on mobile semantic search.
The second part of the event saw Peter F. Patel-Schneider (Nuance) holding a presentation with the title “DBpedia from the Fringe” giving some insights on how DBpedia could be further improved. Shortly after, Sebastian Hellmann, Executive Director of the DBpedia Association, walked the stage and presented the state of the art of the association, including achievements and future goals. Sanjay Krishnan (U.C. Berkeley) talked about the link between AlphaGo and data cleansing. You can find his slides here. Bill Andersen (Volley.com) argued for the use of extremely precise and fine-grained approaches to deal with small data. His presentation is available here. Finally, Michael Grove (Stardog Union) stressed on the view of knowledge graphs as knowledge toolkits backed by a graph data model.

The event concluded with refreshments, snacks and drinks served in the atrium allowing to talk about the presented topics, discuss the latest developments in the field of knowledge graphs and network between all participants. In the end, this closing session was way longer than had been planned.
GSoC Mentor Summit
Shortly after the CA Community Meeting, our DBpedia mentors Tommaso Soru and Magnus Knuth participated at the Google Summer of Code Mentor Summit held in Sunnyvale California. During free sessions hosted by mentors of diverse open source organizations, Tommaso and Magnus presented selected projects during their lightning talks. Beyond open source, open data topics have been targeted in multiple sessions, as this is not only relevant for research, but there is also a strong need in software projects. The meetings paved the way for new collaborations in various areas, e.g. the field of question answering over the DBpedia knowledge corpus, in particular the use of Neural SPARQL Machines for the translation of natural language into structured queries. We expect that this hot deep-learning topic will be featured in the next edition of GSoC projects. Overall, it has been a great experience to meet so many open source fellows from all over the world.
Upcoming events
After the event is before another ….
Connected Data London, November 16th, 2017.
Sebastian Hellmann, executive director of the DBpedia Association will present Data Quality and Data Usage in a large-scale Multilingual Knowledge Graph during the content track at the Connected Data in London. He will also join the panelists in the late afternoon panel discussion about Linked Open Data: Is it failing or just getting out of the blocks? Feel free to join the event and support DBpedia.
A message for all DBpedia enthusiasts – our next Community Meeting
Currently we are planning our next Community Meeting and would like to invite DBpedia enthusiasts and chapters who like to host a meeting to send us their ideas to dbpedia@infai.org. The meeting is scheduled for the beginning of 2018. Any suggestions regarding place, time, program and topics are welcome!
Check our website for further updates, follow us on #twitter or subscribe to our newsletter.
We will keep you posted
Your DBpedia Association
The post Meeting with the US-DBpedians – A Wrap-Up appeared first on DBpedia Association.
]]>