The post New Prototype: Databus Collection Feature appeared first on DBpedia Association.
]]>A new Databus Collection Feature? How come, and how does it work? Read below and find out how using the DBpedia Databus becomes easier by the day and with each new tool.
Motivation
With more and more data being uploaded to the databus we started to develop test applications using that data. The SPARQL endpoint offers a central hub to access all metadata for datasets uploaded to the databus provided you know how to write SPARQL queries. The metadata includes the download links of the data files – it was, therefore, possible to pass a SPARQL query to an application, download the actual data and then use for whatever purpose the app had.
The Databus Collection Editor
The DBpedia Databus now provides an editor for collections. A collection is basically a labelled SPARQL query that is retrievable via URI. Hence, with the collection editor you can group Databus groups and artifacts into a bundle and publish your selection using your Databus account. It is now a breeze to select the data you need, share the exact selection with others and/or use it in existing or self-made applications.
If you are not familiar with SPARQL and data queries, you can think of the feature as a shopping cart for data: You create a new cart, put data in it and tell your friends or applications where to find it. Quite neat, right?
In the following section, we will cover the user interface of the collection editor.
The Editor UI
Firstly, you can find the collection editor by going to the DBpedia Databus and following the Collections link at the top or you can get there directly by clicking here.
What you will see is the following:
General Collection Info
Secondly, since you do not have any collections yet, the editor has already created an empty collection named “Unnamed” for you. At the right side next to the label and description you will find a pen icon. By clicking the icon or the label itself you can edit its content. The collection is not published yet, so the Collection URI is blank.
Whenever you are not logged in or the collection has not been published yet, the editor will also notify you that your changes are only saved in your local browser cache and NOT remotely on our server. Keep that in mind when clearing your cache. Publishing the collection however is easy: Simply log into (or create) your Databus account and hit the publish button in the action bar. This will open up a modal where you can pick your unique collection id and hit publish again. That’s it!
The Collection Info section will now show the collection URI. Following the link will take you to the HTML representation of your collection that will be visible to others. Hitting the Edit button in the action bar will bring you back to the editor.
Collection Hierarchy
Let’s have a look at the core piece of the collection editor: the hierarchy view. A collection can be a bundle of different Databus groups and artifacts but is not limited to that. If you know how to write a SPARQL query, you can easily extend your collection with more powerful selections. Therefore, the hierarchy is split into two nodes:
- Generated Queries: Contains all queries that are generated from your selection in the UI
- Custom Queries: Contains all custom written SPARQL queries
Both, hierarchy nodes have a “+” icon. Clicking on this button will let you add generated or custom queries respectively.
Custom Queries
If you hit the “+” icon on the Custom Queries node, a new node called “Custom Query” will appear in the hierarchy. You can remove a custom query by clicking on the trashcan icon in the hierarchy. If you click the node it will take you to a SPARQL input field where you can edit the query.
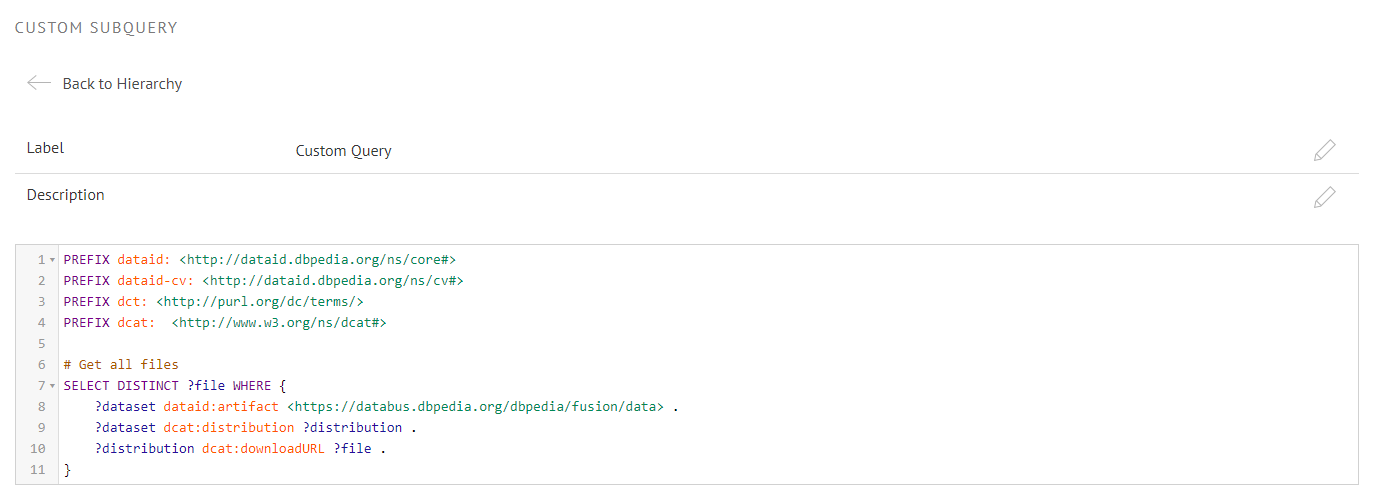
To make your collection more understandable for others, you can even document the query by adding a label and description.
Writing Your Own Custom Queries
A collection query is a SPARQL query of the form:
SELECT DISTINCT ?file WHERE {
{
[SUBQUERY]
}
UNION
{
[SUBQUERY]
}
UNION
...
UNION
{
[SUBQUERY]
}
}All selections made by generated and custom queries will be joined into a single result set with a single column called “file“. Thus it is important that your custom query binds data to a variable called “file” as well.
Generated Queries
Clicking the “+” icon on the Generated Queries node will take you to a search field. Make use of the indexed search on the Databus to find and add the groups and artifacts you need. If you want to refine your search, don’t worry: you can do that in the next step!
Once the artifact or group has been added to your collection, the Add to Collection button will turn green. Once you are done you can go back to the Editor with Back to Hierarchy button.
Your hierarchy will now contain several new nodes.
Group Facets, Artifact Facets and Overrides
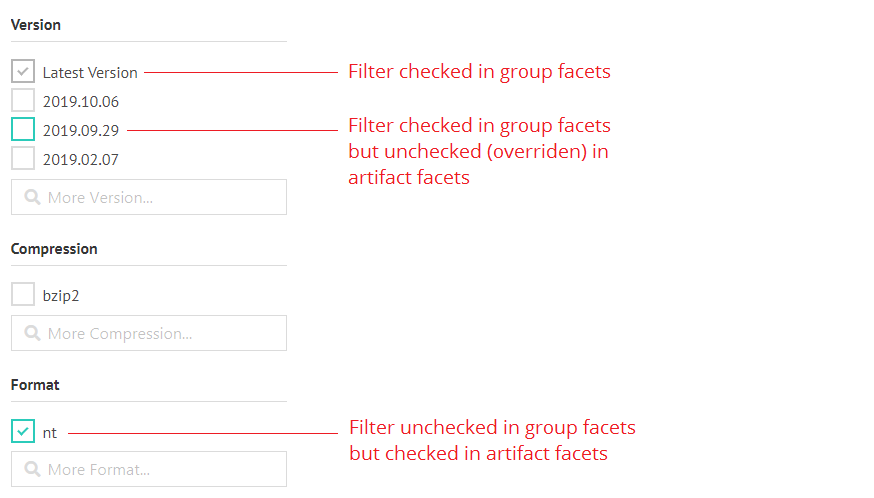
Group and artifacts that have been added to the collection will show up as nodes in the hierarchy. Clicking a node will open a filter where you can refine your dataset selection. Setting a filter to a group node will apply it to all artifact nodes unless you override that setting in any artifact node manually. The filter set in the group node is shown in the artifact facets in dark grey. Any overrides in the artifact facets will be highlighted in green:
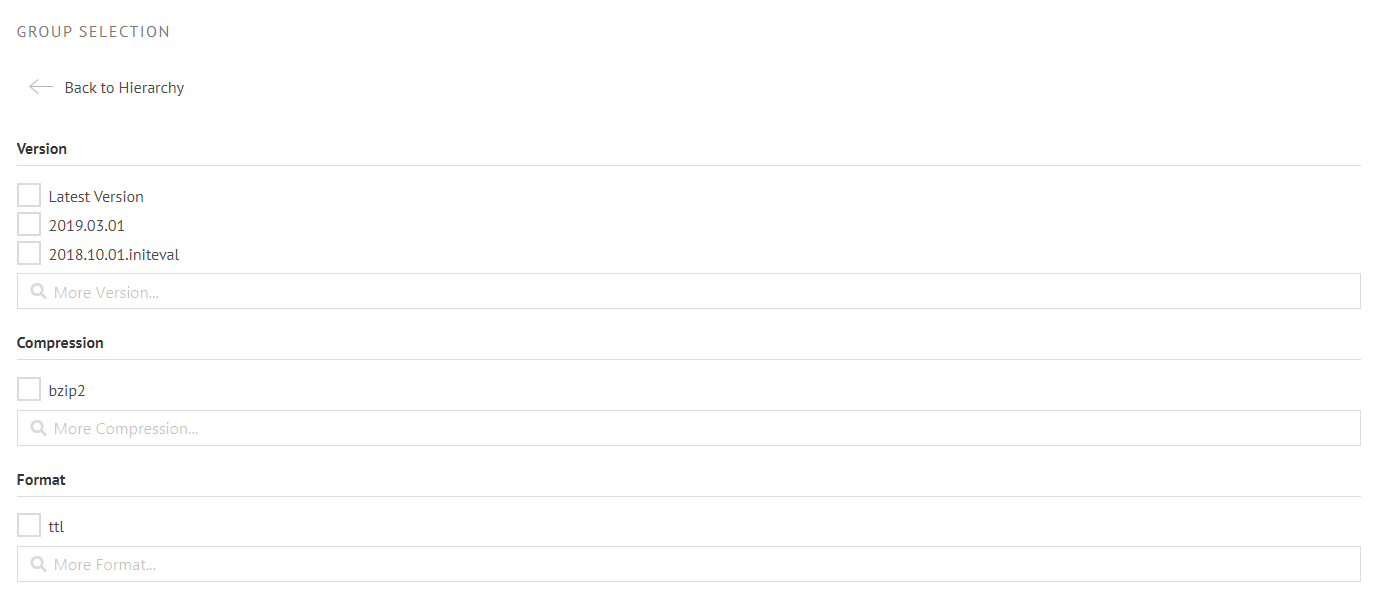
Group Nodes
A group node will provide a list of filters that will be applied to all artifacts of that group:
Artifact Nodes
Artifact nodes will then actually select data files which will be visible in the faceted view. The facets are generated dynamically from the available variants declared in the metadata.
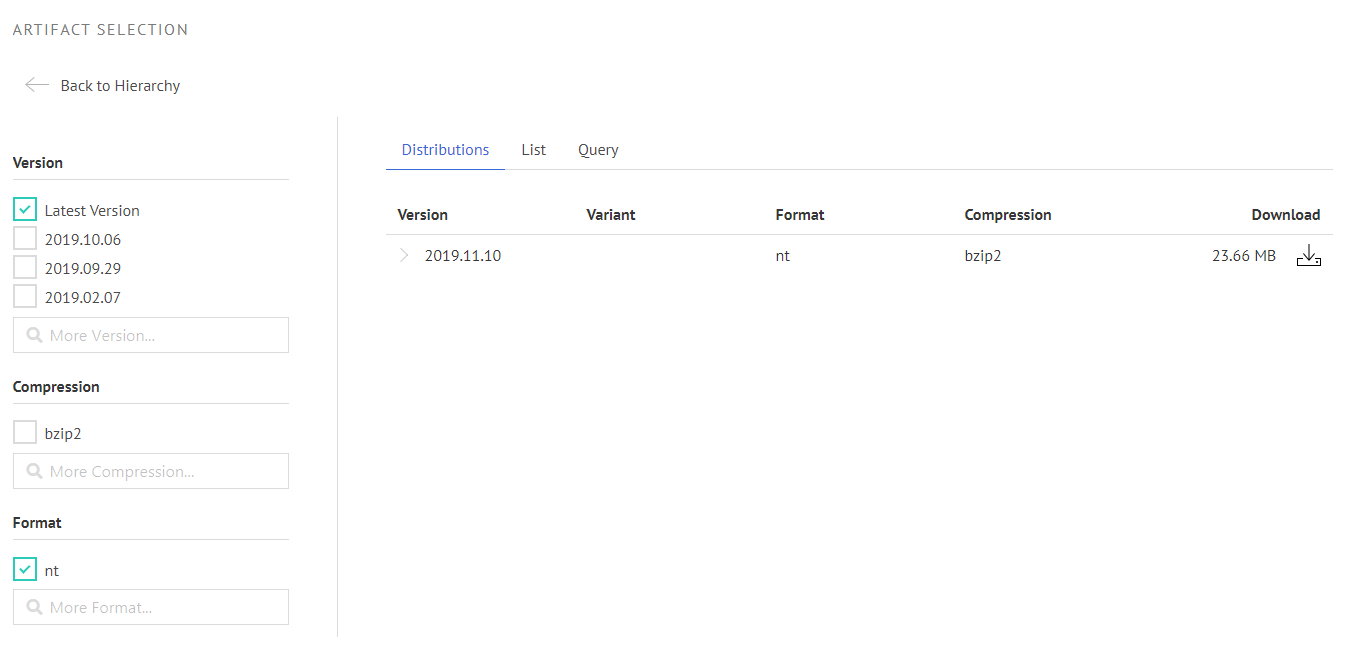
Example: Here we selected the latest version of the databus dump as n-triple. This collection is already in use: The collection URI is passed to the new generic lookup application, which then creates the search function for the databus website. If you are interested in how to configure the lookup application, you can go here: https://github.com/dbpedia/lookup-application. Additionally, there will also be another blog post about the lookup within the next few weeks
Use Cases
The DBpedia Databus Collections are useful in many ways.
- You can share a specific dataset with your community or colleagues.
- You can re-use dataset others created
- You can plug collections into databus-ready applications and avoid spending time on the download and setup process
- You can point to a specific piece of data (e.g. for testing) with a single URI in your publications
- You can help others to create data queries more easily
We hope you enjoy the Databus Collection Feature and we would love to hear your feedback! You can leave your thoughts and suggestions in the new DBpedia Forum. Feedback of any kinds is highly appreciated since we want to improve the prototype as fast and user-driven as possible! Cheers!
A big thanks goes to DBpedia developer Jan Forberg who finalized the Databus Collection Feature and compiled this text.
Yours
DBpedia Association
The post New Prototype: Databus Collection Feature appeared first on DBpedia Association.
]]>The post Global Fact Sync – Synchronizing Wikidata & Wikipedia’s infoboxes appeared first on DBpedia Association.
]]>How is data edited in Wikipedia/Wikidata? Where does it come from? And how can we synchronize it globally?
The GlobalFactSync (GFS) Project — funded by the Wikimedia Foundation — started in June 2019 and has two goals:
- Answer the above-mentioned three questions.
- Build an information system to synchronize facts between all Wikipedia language-editions and Wikidata.
Now we are seven weeks into the project (10+ more months to go) and we are releasing our first prototypes to gather feedback.
How – Synchronization vs Consensus
We follow an absolute “Human(s)-in-the-loop” approach when we talk about synchronization. The final decision whether to synchronize a value or not should rest with a human editor who understands consensus and the implications. There will be no automatic imports. Our focus is to drastically reduce the time to research all references for individual facts.
A trivial example to illustrate our reasoning is the release date of the single “Boys Don’t Cry” (March 16th, 1989) in the English, Japanese, and French Wikipedia, Wikidata and finally in the external open database MusicBrainz. A human editor might need 15-30 minutes finding and opening all different sources, while our current prototype can spot differences and display them in 5 seconds.
We already had our first successful edit where a Wikipedia editor fixed the discrepancy with our prototype: “I’ve updated Wikidata so that all five sources are in agreement.” We are now working on the following tasks:
- Scaling the system to all infoboxes, Wikidata and selected external databases (see below on the difficulties there)
- Making the system:
- “live” without stale information
- “reliable” with less technical errors when extracting and indexing data
- “better referenced” by not only synchronizing facts but also references
Contributions and Feedback
To ensure that GlobalFactSync will serve and help the Wikiverse we encourage everyone to try our data and micro-services and leave us some feedback, either on our Meta-Wiki page or via email. In the following 10+ months, we intend to improve and build upon these initial results. At the same time, these microservices are available to every developer to exploit it and hack useful applications. The most promising contributions will be rewarded and receive the book “Engineering Agile Big-Data Systems”. Please post feedback or any tool or GUI here. In case you need changes to be made to the API, please let us know, too.
For the ambitious future developers among you, we have some budget left that we will dedicate to an internship. In order to apply, just mention it in your feedback post.
Finally, to talk to us and other GlobalfactSync-Users you may want to visit WikidataCon and Wikimania, where we will present the latest developments and the progress of our project.
Data, APIs & Microservices (Technical prototypes)
Data Processing and Infobox Extraction
For GlobalFactSync we use data from Wikipedia infoboxes of different languages, as well as Wikidata, and DBpedia and fuse them to receive one big, consolidated dataset – a PreFusion dataset (in JSON-LD). More information on the fusion process, which is the engine behind GFS, can be found in the FlexiFusion paper. One of our next steps is to integrate MusicBrainz into this process as an external dataset. We hope to implement even more such external datasets to increase the amount of available information and references.
First microservices
We deployed a set of microservices to show the current state of our toolchain.
- [Initial User Interface] The GlobalFactSync UI prototype (available at http://global.dbpedia.org) shows all extracted information available for one entity for different sources. It can be used to analyze the factual consensus between different Wikipedia articles for the same thing. Example: Look at the variety of population counts for Grimma.
- [PreFusion JSON API] While the UI allows simple, fast and easy browsing for one entity at a time, we also provide raw access to the underlying data (PreFusion dump). The query UI (http://global.dbpedia.org:8990 (user: read, pw: gfs) can be utilized to run simple analytical queries. Thus, we can determine the number of locations having at least one population value (1,194,007) but can also focus on examples with data quality problems (e.g. one of the 4,268 locations with more than 10 population values). Moreover, documentation about the PreFusion dataset and the download link for the data are available on the Databus website.
- [Reference Data Download] We ran the Reference Extraction Service over 10 Wikipedia languages. Download dumps here.
- [Reference Extraction Service] Good references are crucial for an import of facts from Wikipedia to Wikidata. We are currently working with colleagues from Poznań University of Economics and Business on reference extraction for facts from Wikipedia. A current development reference extraction microservice shows all references and the location where they were spotted in the Infobox – ad hoc – for a given article: http://dbpedia.informatik.uni-leipzig.de:8111/infobox/references?article=https://en.wikipedia.org/wiki/Facebook&format=json ( ‘&format=tsv’ also available)
- [Infobox Extraction Service] A similar ad hoc extraction of factual information from infoboxes and other Wikipedia article information is available here. This microservice displays information which can be extracted with the help of DBpedia mappings from an infobox e.g. from the German Facebook Wikipedia article: http://dbpedia.informatik.uni-leipzig.de:9998/server/extraction/en/extract?title=Facebook&revid=&format=trix&extractors=mappings. See here for more options: http://dbpedia.informatik.uni-leipzig.de:9999/server/extraction/.
- [ID service] Last but not least, we offer the Global ID Resolution Service. It ties together all available identifiers for one thing (i.e. at the moment all DBpedia/Wikipedia and Wikidata identifiers – MusicBrainz coming soon…) and shows their stable DBpedia Global ID.
Finding sync targets
In order to test out our algorithms, we started by looking at various groups of subjects, our so-called sync targets. Based on the different subjects a set of problems were identified with varying layers of complexity:
- identity check/check for ambiguity — Are we talking about the same entity?
- fixed vs. varying property — Some properties vary depending on nationality (e.g., release dates), or point in time (e.g., population count).
- reference — Depending on the entity’s identity check and the property’s fixed or varying state the reference might vary. Also, for some targets, no query-able online reference might be available.
- normalization/conversion of values — Depending on language/nationality of the article properties can have varying units (e.g., currency, metric vs imperial system).
The check for ambiguity is the most crucial step to ensure that the infoboxes that are being compared do refer to the same entity. We found, instances where the Wikipedia page and the infobox shown on that page were presenting information about different subjects (e.g., see here).
Examples
As a good sync target to start with the group ‘NBA players’ was identified. There are no ambiguity issues, it is a clearly defined group of persons, and the amount of varying properties is very limited. Information seems to be derived from mainly two web sites (nba.com and basketball-reference.com) and normalization is only a minor issue. ‘Video games’ also proved to be an easy sync target, with the main problem being varying properties such as different release dates for different platforms (Microsoft Windows, Linux, MacOS X, XBox) and different regions (NA vs EU).
More difficult topics, such as ‘cars’, ’music albums’, and ‘music singles’ showed more potential for ambiguity as well as property variability. A major concern we found was Wikipedia pages that contain multiple infoboxes (often seen for pages referring to a certain type of car, such as this one). Reference and fact extraction can be done for each infobox, but currently, we run into trouble once we fuse this data.
Further information about sync targets and their challenges can be found on our Meta-Wiki discussion page, where Wikipedians that deal with infoboxes on a regular basis can also share their insights on the matter. Some issues were also found regarding the mapping of properties. In order to make GlobalFactSync as applicable as possible, we rely on the DBpedia community to help us improve the mappings. If you are interested in participating, we will connect with you at http://mappings.dbpedia.org and in the DBpedia forum.
Bottomline – We value your feedback
Your DBpedia Association
The post Global Fact Sync – Synchronizing Wikidata & Wikipedia’s infoboxes appeared first on DBpedia Association.
]]>