The post FinScience: leveraging DBpedia tools for fintech applications appeared first on DBpedia Association.
]]>by FinScience
A brief presentation of who we are
FinScience is an Italian data-driven fintech company founded in 2017 in Milan by Google’s former senior managers and Alternative Data experts, who have combined their digital and financial expertise. FinScience, thus, originates from this merger of the world of Finance and the world of Data Science.
The company leverages founders’ experiences concerning Data Governance, Data Modeling and Data Platforms solutions. These are further enriched through the tech role in the European Consortium SSIX (Horizon 2020 program) focused on the building of a Social Sentiment for financial purposes. FinScience applies proprietary AI-based technologies to combine financial data/insights with alternative data in order to generate new investment ideas, ESG scores and non-conventional lists of companies that can be included in investment products by financial operators.
The FinScience’s data analysis pipeline is strongly grounded on the DBpedia ontology: the greatest value, according to our experience, is given by the possibility to connect knowledge in different languages, to query automatically-extracted structured information and to have rather frequently updated models.
Products and solutions
FinScience daily retrieves content from the web. About 1.5 million web pages are visited every day on about 35.000 different domains. The content of these pages is extracted, interpreted and analysed via Natural Language Processing techniques to identify valuable information and sources. Thanks to the structured information based on the DBpedia ontology, we can apply our proprietary AI algorithms to suggest to our customers the right investment opportunities.Our products are mainly based on the integration of this purely digital data – we call it “alternative data”- with traditional sources coming from the world of finance and sustainability. We describe these products briefly:
- FinScience Platform for traders: it leverages the power of machine learning to help traders monitor specific companies, spot new trends in the financial market, give access to an high added-value selection of companies and themes.
- ESG scoring: we provide an assessment of corporate ESG performance, by combining internal data (traditional, self-disclosed data) with external ‘alternative’ data (stakeholder-generated data) in order to measure the gap between what the companies communicate and what is stakeholder perception related to corporate sustainability commitments.
- Thematic selections of listed companies : we create Trend-Driven selections oriented towards innovative themes: our data, together with the analysis of financial specialists, contribute to the selection of a set of listed companies related to trending themes such as the Green New Deal, the 5G technology or new medtech applications.
FinScience and DBpedia
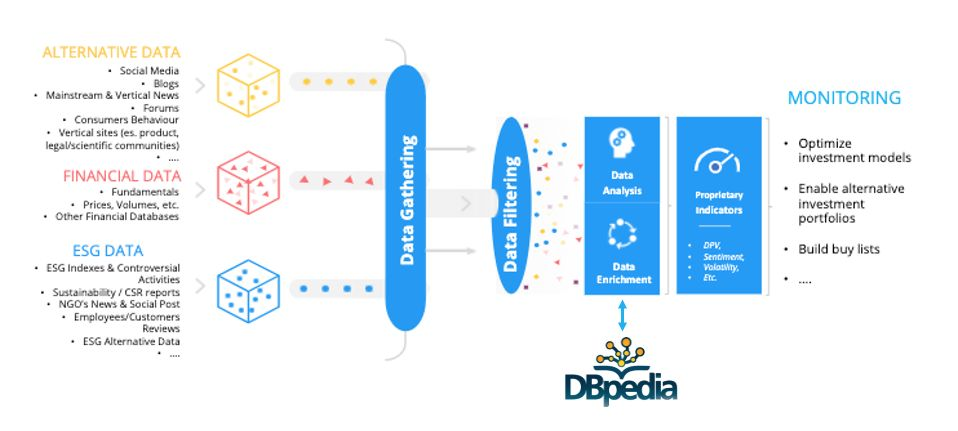
As mentioned before, FinScience is strongly grounded in the DBpedia ontology, since we employ Spotlight to perform Named Entity Recognition (NER), namely automatic annotation of entities in a text. The NER task is performed with a two step procedure. The first step consists in annotating the named entity of a text using DBpedia Spotlight. In particular, Spotlight links a mention in the text (that is identified by its name and its context within the text) to the DBpedia entity that maximizes the joint probability of occurrence of both. The model is pre-trained on texts extracted from Wikipedia. Note that each entity is represented by a link to a DBpedia page (see, e.g. http://dbpedia.org/page/Eni ), a DBpedia type indicating the type of the entity according to this ontology and other information.
Another interesting feature of this approach is that we have a one to one mapping of the italian and english entities (and in general any language supported by DBpedia), allowing us to have a unified representation of an entity in the two languages. We are able to obtain this kind of information by exploiting the potential of DBpedia Virtuoso, which allows us to access DBpedia dataset via SPARQL. By identifying the entities mentioned in the online content, we can understand which topics are mentioned and thus identify companies and trends that are spreading in the digital ecosystem as well as analyzing how they are related to each other.
Challenges and next steps
One of the toughest challenges for us is to find an optimal way to update the models used by DBpedia Spotlight. Every day new entities and concepts arise and we are willing to recognise them in the news we analyze. And that is not all. In addition to recognizing new concepts, we need to be able to track an entity through all the updated versions of the model. In this way, we will not only be able to identify entities, but we will also have evidence of when some concepts were first generated. And we will know how they have changed over time, regardless of the names that have been used to identify them.
We are strongly involved in the DBpedia community and we try to contribute with our know-how. Particularly FinScience will contribute on infrastructure and Dockerfiles as well as on finding issues on the new released project (for instance, wikistats-extractor).
A big thank you to FinSciene for presenting their products, challenges and contribution to DBpedia.
Yours,
DBpedia Association
The post FinScience: leveraging DBpedia tools for fintech applications appeared first on DBpedia Association.
]]>