The post The Diffbot Knowledge Graph and Extraction Tools appeared first on DBpedia Association.
]]>by Diffbot
Diffbot’s mission to “structure the world’s knowledge” began with Automatic Extraction APIs meant to pull structured data from most pages on the public web by leveraging machine learning rather than hand-crafted rules.
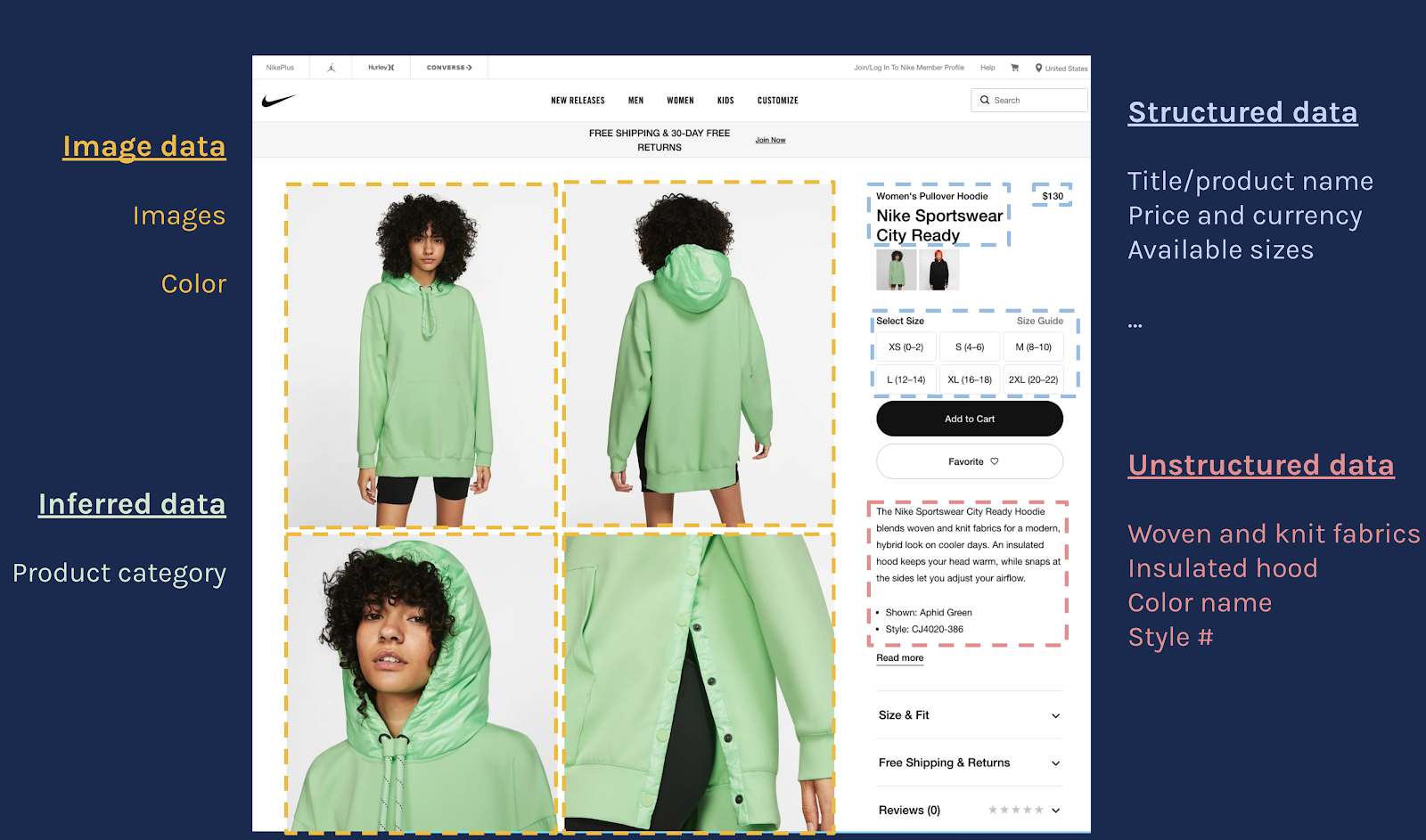
More recently, Diffbot has emerged as one of only three Western entities to crawl a vast majority of the web, utilizing our Automatic Extraction APIs to make the world’s largest commercially-available Knowledge Graph.
A Knowledge Graph At The Scale Of The Web
The Diffbot Knowledge Graph is automatically constructed by crawling and extracting data from over 60 billion web pages. It currently represents over 10 billion entities and 1 trillion facts about People, Organizations, Products, Articles, Events, among others.
Users can access the Knowledge Graph programmatically through an API. Other ways to access the Knowledge Graph include a visual query interface and a range of integrations (e.g., Excel, Google Sheets, Tableau).

Whether you’re consuming Diffbot KG data in a visual “low code” way or programmatically, we’ve continually added features to our powerful query language (Diffbot Query Language, or DQL) to allow users to “query the web like a database.”
Guilt-Free Public Web Data
Current use cases for Diffbot’s Knowledge Graph and web data extraction products run the gamut and include data enrichment; lead enrichment; market intelligence; global news monitoring; large-scale product data extraction for ecommerce and supply chain; sentiment analysis of articles, discussions, and products; and data for machine learning. For all of the billions of facts in Diffbot’s KG, data provenance is preserved with the original source (a public URL) of each fact.
Entities, Relationships, and Sentiment From Private Text Corpora
The team of researchers at Diffbot has been developing new natural language processing techniques for years to improve their extraction and KG products. In October 2020, Diffbot made this technology commercially-available to all via the Natural Language API.
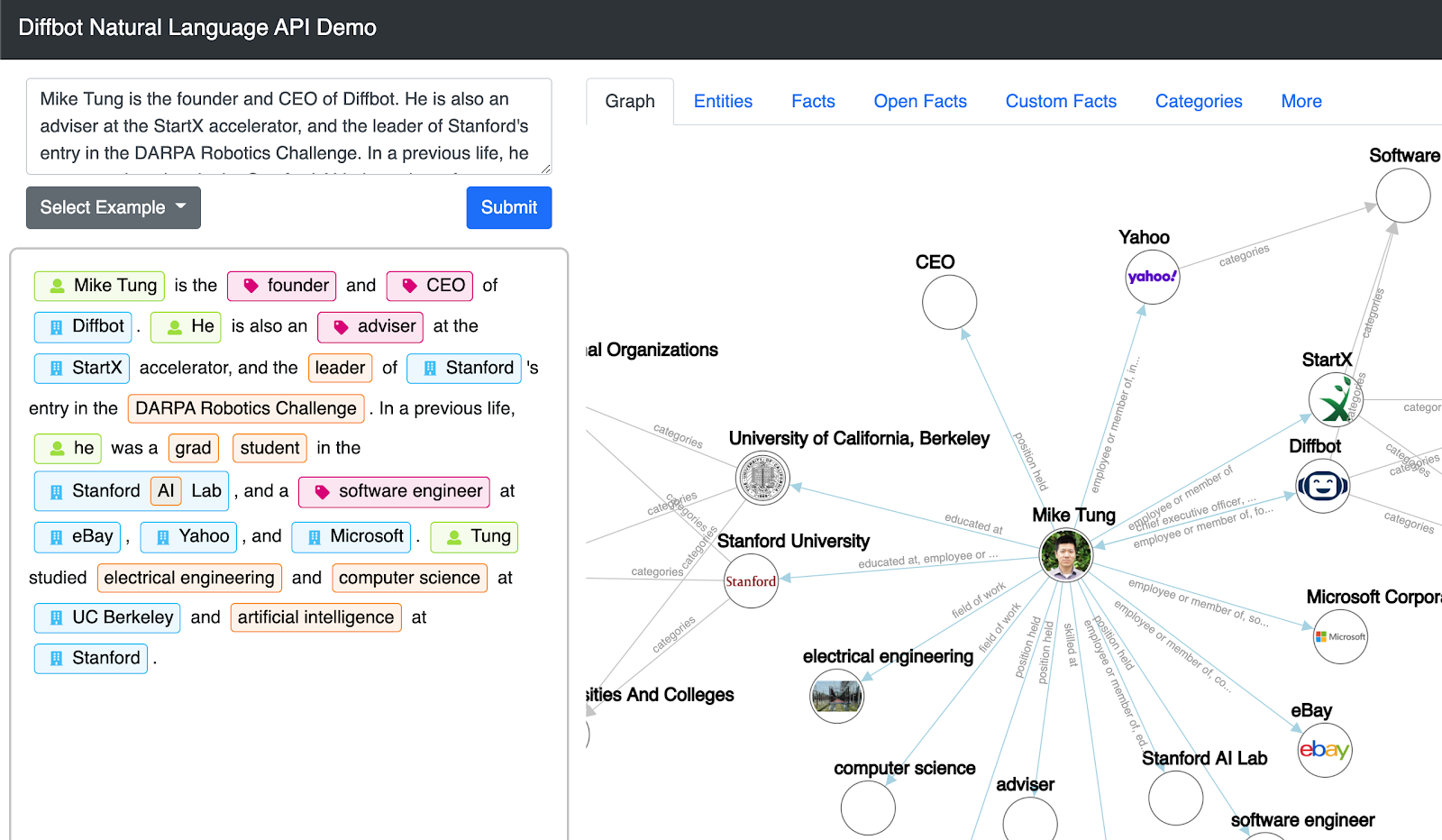
Our Natural Language API pulls out entities, relationships/facts, categories and sentiment from free-form texts. This allows organizations to turn unstructured texts into structured knowledge graphs.
Diffbot and DBpedia
In addition to extracting data from web pages, Diffbot’s Knowledge Graph compiles public web data from many structured sources. One important source of knowledge is DBpedia. Diffbot also contributes to DBpedia by providing access to our extraction and KG services and collaborating with researchers in the DBpedia community. For a recent collaboration between DBpedia and Diffbot, be sure to check out the Diffbot track in DBpedia’s Autumn Hackathon for 2020.
A big thank you to Diffbot, especially Filipe Mesquita for presenting their innovative Knowledge Graph.
Yours,
DBpedia Association
The post The Diffbot Knowledge Graph and Extraction Tools appeared first on DBpedia Association.
]]>The post Ontotext GraphDB on DBpedia appeared first on DBpedia Association.
]]>by Milen Yankulov from Ontotext
GraphDB is a family of highly efficient, robust, and scalable RDF databases. It streamlines the load and use of linked data cloud datasets, as well as your own resources. For easy use and compatibility with the industry standards, GraphDB implements the RDF4J framework interfaces, the W3C SPARQL Protocol specification, and supports all RDF serialization formats. The database offers open source API and it is the preferred choice of both small independent developers and big enterprise organizations because of its community and commercial support, as well as excellent enterprise features such as cluster support and integration with external high-performance search applications – Lucene, Solr, and Elasticsearch. GraphDB is build 100% on Java in order to be OS Platform independent.
GraphDB is one of the few triplestores that can perform semantic inferencing at scale, allowing users to derive new semantic facts from existing facts. It handles massive loads, queries, and inferencing in real-time.
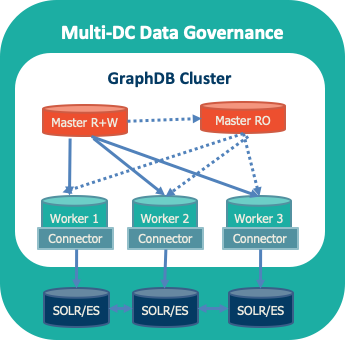
GDB Architecture
GraphDB Workbench
Workbench is the GraphDB web-based administration tool. The user interface is similar to the RDF4J Workbench Web Application, but with more functionality.
GraphDB Engine
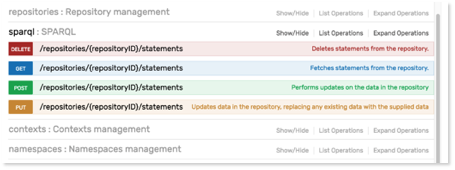
The GraphDB Workbench REST API can be used for managing locations and repositories programmatically, as well as managing a GraphDB cluster. It includes connecting to remote GraphDB instances (locations), activating a location, and different ways for creating a repository.
It includes also connecting workers to masters, connecting masters to each other, as well monitoring the state of a cluster.
GraphQL access via Ontotext Platform 3
GraphDB enables Knowledge Graph access and updates via GraphQL. GraphDB is extended to support the efficient processing of GraphQL queries and mutations to avoid the N+1 translation of nested objects to SPARQL queries.

Ontotext offers three editions of GraphDB: Free, Standard, and Enterprise.
Free – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server with a limit of two concurrent queries.
Standard Edition (SE) – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server and an unlimited number of concurrent queries.
Enterprise Edition (EE) – high-availability cluster with worker and master database implementation for resilience and high-performance parallel query answering.
Why GraphDB is preferred choice of many data architects and data ops?
3 Reasons:
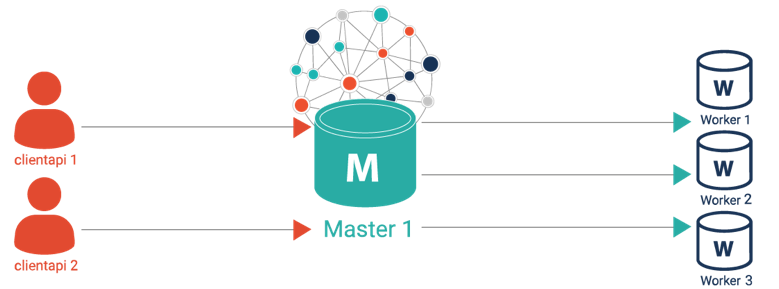
1. High Availability Cluster Architecture
GraphDB offers you a high-performance cluster proven to scale in production environments. It supports
- (1) coordinating all read and write operations,
- (2) ensuring that all worker nodes are synchronized,
- (3) propagating updates (insert and delete tasks) across all workers and checking updates for inconsistencies,
- (4) load balancing read requests between all available worker nodes
Improved resilience
failover, dynamic configuration
Improved query bandwidth
larger cluster means more queries per unit time
Deployable across multiple data centres
Elastic scaling in cloud environments
Integration with search engines
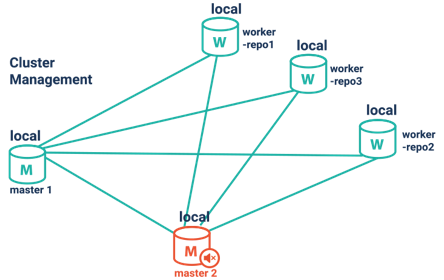
Cluster Management and Monitoring
It supports
(1) automatic cluster reconfiguration in the event of failure of one or more worker nodes,
(2) a smart client supporting multiple endpoints.
2. Easy Setup
GraphDB is 100% Java based in order to be Platform Independent. It is available through Native Installation Packages or Open Maven. It supports also Puppet and could be Dockerized. GraphDB is Cloud agnostic – It could be deployd on AWS, Azure, Google Cloud, etc.
3. Support
Based on the Edition you are using you could use the Community Support (StackOverFlow monitoring)
Ontotext has its Dedicated Support Team tha could assist through Customized Runbooks, Easy Slack communication, Jira Issue-Tracking System
A big thank you to Ontotext for providing some insights into their product and database.
Yours,
DBpedia Association
The post Ontotext GraphDB on DBpedia appeared first on DBpedia Association.
]]>