The post Giving knowledge back to Wikipedia: Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources appeared first on DBpedia Association.
]]>When DBpedia started over 13 years ago, two major impacts were made:
- It was the first showcase of the potential of open knowledge graphs through the semantification of Wikipieda’s knowledge which proved useful for the development of thousands of Semantic Web applications and technologies (such as DBpedia Mobile from 2008, long before any knowledge-rich map viewers existed).
- DBpedia played a major role as a nucleus, glueing the de-central web of data together into what has grown into the largest (de-centrally-stored, constantly updated) knowledge graph on earth – the linked data web.
Giving knowledge back to Wikipedia
Wikimedia Grant
We received a Wikimedia Grant for our project GlobalFactSyncRE and re-iterated the issue again. After almost two years of working on the topic, we would like to announce our final report. We submitted a summary of this report to the Qurator conference:
Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources. Sebastian Hellmann, Johannes Frey, Marvin Hofer, Milan Dojchinovski, Krzysztof Wecel and Włodzimierz Lewoniewski.
Please find our self-archived e-print here.
Upcoming Presentation
Don’t miss the talk: Thur, Feb 11th, 2021 @ 10:45 a.m. CET/UTC + 1 as part of the Qurator Conference. Advance registration (for the Scientific Workshop I) necessary.
Highlights of the paper
- In sum, we laid a good foundation, but also have many things unfinished. The good thing about the paper is that it brings together many aspects that require attention and drafts a roadmap to bring external data into Wikipedia from Linked Data via DBpedia.
- Wikipedia’s infoboxes are still growing a lot. Overall, 150 % in the largest 140 Wikipedias and 200 % for English over the last 3 years.
- We could extract and analyse 725 million infobox facts from the largest 140 Wikipedias and 8.8 million references from the largest 11 Wikipedias.
- We compared existing data in Wikidata with infoboxes from 40 Wikipedias for ~200 infobox parameters and only found a 20% overlap. Wikidata needs to grow quite a lot in the right direction to be fit to replace the rich and growing infoboxes in Wikipedia, it seems.
Read the submitted paper here.
Have fun browsing our new website. Stay safe and check Twitter, LinkedIn and our Website or subscribe to our Newsletter for the latest news and information.
Yours,
DBpedia Association
The post Giving knowledge back to Wikipedia: Towards a Systematic Approach to Sync Factual Data across Wikipedia, Wikidata and External Data Sources appeared first on DBpedia Association.
]]>The post ImageSnippets and DBpedia appeared first on DBpedia Association.
]]>The following post introduces to you ImageSnippets and how this tool profits from the use of DBpedia.
ImageSnippets – A Tool for Image Curation

For over two decades, ImageSnippets has been evolving as an ontology and data-driven framework for image annotation research. Representing the informal knowledge people have about the context and provenance of images as RDF/linked data is challenging, but it has also been an enlightening and engaging journey in not only applying formal semantic web theory to building image graphs but also to weave together our interests with what others have been doing in the field of semantic annotation and knowledge graph building over these many years.
DBpedia provides the entities for our RDF descriptions
Since the beginning, we have always made use of DBpedia and other publicly available datasets to provide the entities for use in our RDF descriptions. Though ImageSnippets can be used to build special vocabularies around niche domains, our primary research is around relation ontology building and we prefer to avoid the creation of new entities unless we absolutely can not find them through any other service.

When we first went live with our basic system in 2013, we began hand-building tens of thousands of triples using terms primarily from DBpedia (the core of the linked data cloud.) While there would often be an overlap of terms with other datasets – almost a case of too many choices – we formed a best practice of preferentially using DBpedia terms as often as possible, because they gave us the most utility for reasoning using the SKOS concepts built into the DBpedia service. We have also made extensive use of DBpedia Spotlight for named-entity extraction.
How to combine DBpedia & Wikidata and make it useful for ImageSnippets
But the addition of the Wikidata Query Service over the past 18 months or so has now given us an even more unique challenge: how to work with both! Since DBpedia and Wikidata both have class relationships that we can reason from, we found ourselves in a position to be able to examine both DBpedia and Wikidata in concert with each other through the use of mapping techniques between the two datasets.
How it works: ImageSnippets & DBpedia
When an image is saved, we build inference graphs over results from both DBpedia and Wikidata. These graphs can be revealed with simple SPARQL queries at our endpoint and queries from subclasses, taxons and SKOS concepts can find image results in our custom search tool. We have also just recently added a pathfinder utility – highly useful for semantic explainability as it will return the precise path of connections from an originating source entity to the target entity that was used in our custom image search.
Sometimes a query will produce very unintuitive results, and the pathfinder tool enables us to quickly locate semantic errors which lead to clearly erroneous misclassifications (for example, a search for the Wikidata subclass of ‘communication medium’ reveals images of restaurants and hotels because of misclassifications in Wikidata.) In this way we can quickly troubleshoot the results of queries, using the images as visual cues to explore the accuracy of the semantic modelling in both datasets.
We are very excited with the new directions that we feel can come of our knitting together of the two knowledge graphs through the use of our visual interface and believe there is a great potential for ImageSnippets to serve a more complex role in cleaning and aligning the two datasets, using the images as our guides.
A big thank you to Margaret Warren for providing some insights into her work at ImageSnippets.
Yours,
DBpedia Association
The post ImageSnippets and DBpedia appeared first on DBpedia Association.
]]>The post GlobalFactSync and WikiDataCon2019 appeared first on DBpedia Association.
]]>Short Project Intro
Funded by the Wikimedia Foundation, the project started in June 2019 and has two goals:
- Answer the following questions:
- How is data edited in Wikipedia and Wikidata?
- Where does it come from?
- How can we synchronize it globally?
- Build an information system to synchronize facts between all Wikipedia language-editions, Wikidata, DBpedia and eventually multiple external sources, while also providing respective references.
In order to help Wikipedians to maintain their infoboxes, check for factual correctness, and also improve data in Wikidata, we use data from Wikipedia infoboxes of different languages, Wikidata, and DBpedia and fuse them into our PreFusion dataset (in JSON-LD). More information on the fusion process, which is the engine behind GFS, can be found in the FlexiFusion paper.
Can’t join the conference or want to find out more about GlobalFactSync?
No problem, the poster we are presenting at the conference is currently available here and will soon be available here. Additionally, why not go through our project timeline, follow up on our progress so far and find out what’s coming up next.
In case you have specific questions regarding GlobalfactSync or even some helpful feedback just ping us via dbpedia@infai.org. We also have our new DBpedia Forum, home to the DBpedia Comunity, which just waits for you to initialize a discussion around GlobalFactSync. Why not start it now?
For general DBpedia news and updates follow us on Twitter.
…And if you are in Berlin at WikiDataCon2019 stop by our poster and talk to our developers. They are looking forward to vital exchanges with you.
All the best
yours,
DBpedia Association
The post GlobalFactSync and WikiDataCon2019 appeared first on DBpedia Association.
]]>The post Global Fact Sync – Synchronizing Wikidata & Wikipedia’s infoboxes appeared first on DBpedia Association.
]]>How is data edited in Wikipedia/Wikidata? Where does it come from? And how can we synchronize it globally?
The GlobalFactSync (GFS) Project — funded by the Wikimedia Foundation — started in June 2019 and has two goals:
- Answer the above-mentioned three questions.
- Build an information system to synchronize facts between all Wikipedia language-editions and Wikidata.
Now we are seven weeks into the project (10+ more months to go) and we are releasing our first prototypes to gather feedback.
How – Synchronization vs Consensus
We follow an absolute “Human(s)-in-the-loop” approach when we talk about synchronization. The final decision whether to synchronize a value or not should rest with a human editor who understands consensus and the implications. There will be no automatic imports. Our focus is to drastically reduce the time to research all references for individual facts.
A trivial example to illustrate our reasoning is the release date of the single “Boys Don’t Cry” (March 16th, 1989) in the English, Japanese, and French Wikipedia, Wikidata and finally in the external open database MusicBrainz. A human editor might need 15-30 minutes finding and opening all different sources, while our current prototype can spot differences and display them in 5 seconds.
We already had our first successful edit where a Wikipedia editor fixed the discrepancy with our prototype: “I’ve updated Wikidata so that all five sources are in agreement.” We are now working on the following tasks:
- Scaling the system to all infoboxes, Wikidata and selected external databases (see below on the difficulties there)
- Making the system:
- “live” without stale information
- “reliable” with less technical errors when extracting and indexing data
- “better referenced” by not only synchronizing facts but also references
Contributions and Feedback
To ensure that GlobalFactSync will serve and help the Wikiverse we encourage everyone to try our data and micro-services and leave us some feedback, either on our Meta-Wiki page or via email. In the following 10+ months, we intend to improve and build upon these initial results. At the same time, these microservices are available to every developer to exploit it and hack useful applications. The most promising contributions will be rewarded and receive the book “Engineering Agile Big-Data Systems”. Please post feedback or any tool or GUI here. In case you need changes to be made to the API, please let us know, too.
For the ambitious future developers among you, we have some budget left that we will dedicate to an internship. In order to apply, just mention it in your feedback post.
Finally, to talk to us and other GlobalfactSync-Users you may want to visit WikidataCon and Wikimania, where we will present the latest developments and the progress of our project.
Data, APIs & Microservices (Technical prototypes)
Data Processing and Infobox Extraction
For GlobalFactSync we use data from Wikipedia infoboxes of different languages, as well as Wikidata, and DBpedia and fuse them to receive one big, consolidated dataset – a PreFusion dataset (in JSON-LD). More information on the fusion process, which is the engine behind GFS, can be found in the FlexiFusion paper. One of our next steps is to integrate MusicBrainz into this process as an external dataset. We hope to implement even more such external datasets to increase the amount of available information and references.
First microservices
We deployed a set of microservices to show the current state of our toolchain.
- [Initial User Interface] The GlobalFactSync UI prototype (available at http://global.dbpedia.org) shows all extracted information available for one entity for different sources. It can be used to analyze the factual consensus between different Wikipedia articles for the same thing. Example: Look at the variety of population counts for Grimma.
- [PreFusion JSON API] While the UI allows simple, fast and easy browsing for one entity at a time, we also provide raw access to the underlying data (PreFusion dump). The query UI (http://global.dbpedia.org:8990 (user: read, pw: gfs) can be utilized to run simple analytical queries. Thus, we can determine the number of locations having at least one population value (1,194,007) but can also focus on examples with data quality problems (e.g. one of the 4,268 locations with more than 10 population values). Moreover, documentation about the PreFusion dataset and the download link for the data are available on the Databus website.
- [Reference Data Download] We ran the Reference Extraction Service over 10 Wikipedia languages. Download dumps here.
- [Reference Extraction Service] Good references are crucial for an import of facts from Wikipedia to Wikidata. We are currently working with colleagues from Poznań University of Economics and Business on reference extraction for facts from Wikipedia. A current development reference extraction microservice shows all references and the location where they were spotted in the Infobox – ad hoc – for a given article: http://dbpedia.informatik.uni-leipzig.de:8111/infobox/references?article=https://en.wikipedia.org/wiki/Facebook&format=json ( ‘&format=tsv’ also available)
- [Infobox Extraction Service] A similar ad hoc extraction of factual information from infoboxes and other Wikipedia article information is available here. This microservice displays information which can be extracted with the help of DBpedia mappings from an infobox e.g. from the German Facebook Wikipedia article: http://dbpedia.informatik.uni-leipzig.de:9998/server/extraction/en/extract?title=Facebook&revid=&format=trix&extractors=mappings. See here for more options: http://dbpedia.informatik.uni-leipzig.de:9999/server/extraction/.
- [ID service] Last but not least, we offer the Global ID Resolution Service. It ties together all available identifiers for one thing (i.e. at the moment all DBpedia/Wikipedia and Wikidata identifiers – MusicBrainz coming soon…) and shows their stable DBpedia Global ID.
Finding sync targets
In order to test out our algorithms, we started by looking at various groups of subjects, our so-called sync targets. Based on the different subjects a set of problems were identified with varying layers of complexity:
- identity check/check for ambiguity — Are we talking about the same entity?
- fixed vs. varying property — Some properties vary depending on nationality (e.g., release dates), or point in time (e.g., population count).
- reference — Depending on the entity’s identity check and the property’s fixed or varying state the reference might vary. Also, for some targets, no query-able online reference might be available.
- normalization/conversion of values — Depending on language/nationality of the article properties can have varying units (e.g., currency, metric vs imperial system).
The check for ambiguity is the most crucial step to ensure that the infoboxes that are being compared do refer to the same entity. We found, instances where the Wikipedia page and the infobox shown on that page were presenting information about different subjects (e.g., see here).
Examples
As a good sync target to start with the group ‘NBA players’ was identified. There are no ambiguity issues, it is a clearly defined group of persons, and the amount of varying properties is very limited. Information seems to be derived from mainly two web sites (nba.com and basketball-reference.com) and normalization is only a minor issue. ‘Video games’ also proved to be an easy sync target, with the main problem being varying properties such as different release dates for different platforms (Microsoft Windows, Linux, MacOS X, XBox) and different regions (NA vs EU).
More difficult topics, such as ‘cars’, ’music albums’, and ‘music singles’ showed more potential for ambiguity as well as property variability. A major concern we found was Wikipedia pages that contain multiple infoboxes (often seen for pages referring to a certain type of car, such as this one). Reference and fact extraction can be done for each infobox, but currently, we run into trouble once we fuse this data.
Further information about sync targets and their challenges can be found on our Meta-Wiki discussion page, where Wikipedians that deal with infoboxes on a regular basis can also share their insights on the matter. Some issues were also found regarding the mapping of properties. In order to make GlobalFactSync as applicable as possible, we rely on the DBpedia community to help us improve the mappings. If you are interested in participating, we will connect with you at http://mappings.dbpedia.org and in the DBpedia forum.
Bottomline – We value your feedback
Your DBpedia Association
The post Global Fact Sync – Synchronizing Wikidata & Wikipedia’s infoboxes appeared first on DBpedia Association.
]]>The post timbr – the DBpedia SQL Semantic Knowledge Platform appeared first on DBpedia Association.
]]>In part three of DBpedia’s growth hack blog series, we feature timbr, the latest development at DBpedia in collaboration with WPSemantix. Read on to find out how it works.
timbr – DBpedia SQL Semantic Knowledge Platform
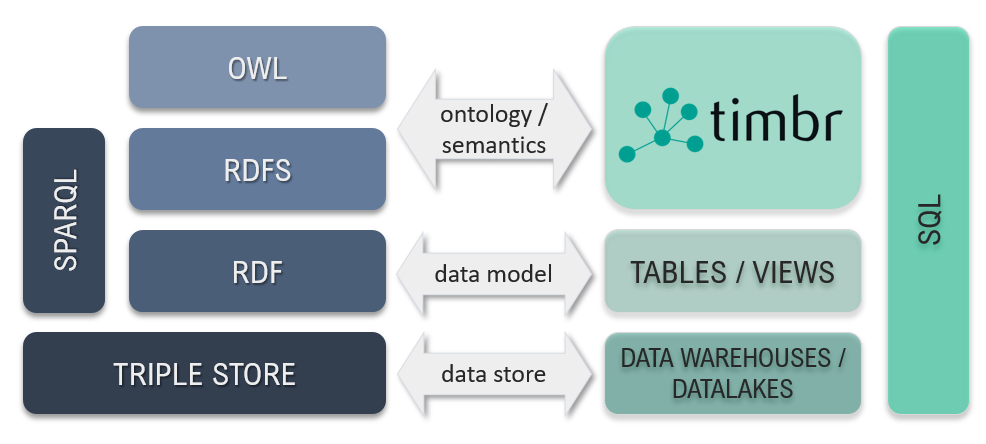
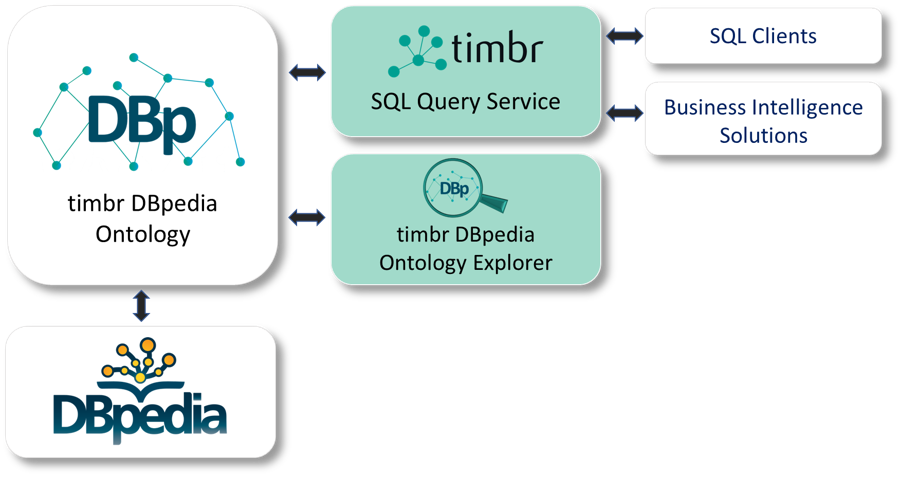
Tel Aviv, Israel and Leipzig, Germany – July 18, 2019 – WP-Semantix (WPS) – the “SQL Knowledge Graph Company ” and DBpedia Association – Institut für Angewandte Informatik e.V., announced today the launch of the timbr-DBpedia SQL Semantic Knowledge Platform, a unique version of WPS’ timbr SQL Semantic Knowledge Graph that integrates timbr-DBpedia ontology, timbr’s ontology explorer/visualizer and timbr’s SQL query service, to provide for the first time semantic access to DBpedia knowledge in SQL and to thus facilitate DBpedia knowledge integration into standard data warehouses and data lakes.
” and DBpedia Association – Institut für Angewandte Informatik e.V., announced today the launch of the timbr-DBpedia SQL Semantic Knowledge Platform, a unique version of WPS’ timbr SQL Semantic Knowledge Graph that integrates timbr-DBpedia ontology, timbr’s ontology explorer/visualizer and timbr’s SQL query service, to provide for the first time semantic access to DBpedia knowledge in SQL and to thus facilitate DBpedia knowledge integration into standard data warehouses and data lakes.
DBpedia
DBpedia is the crowd-sourced community effort to extract structured content from the information created in various Wikimedia projects and publish these as files on the Databus and via online databases. This structured information resembles an open knowledge graph which has been available for everyone on the Web for over a decade. Knowledge graphs are a new kind of databases developed to store knowledge in a machine-readable form, organized as connected, relationship-rich data. After the publication of DBpedia (in parallel to Freebase) 12 years ago, knowledge graphs have become very successful and Google uses a similar approach to create the knowledge cards displayed in search results.
Query the world’s knowledge in standard SQL
Amit Weitzner, founder and CEO at WPS commented: “Knowledge graphs use specialized languages, require resource-intensive, dedicated infrastructure and require costly ETL operations. That is, they did until timbr came along. timbr employs SQL – the most widely known database language, to eliminate the technological barriers to entry for using knowledge graphs and to implement Semantic Web principles to provide knowledge graph functionality in SQL. timbr enables modelling of data as connected, context-enriched concepts with inference and graph traversal capabilities while being queryable in standard SQL, to represent knowledge in data warehouses and data lakes. timbr-DBpedia is our first vertical application and we are very excited by the prospects of our cooperation with the DBpedia team to enable the largest user base to query the world’s knowledge in standard SQL.”
Sebastian Hellmann, executive director of the DBpedia Association commented that:
“our vision of the DBpedia Databus – transforming Linked Data into a networked data economy, is becoming a reality thanks to tools such as timbr-DBpedia which take full advantage of our unique data sets and data architecture. We look forward to working with WPS to also enable access to new data sets as they become available .”
timbr will help to explore the power of semantic technologies
Prof. James Hendler, pioneer and a world-leading authority in Semantic Web technologies and WPS’ advisory board member commented “timbr can be a game-changing solution by enabling the semantic inference capabilities needed in many modelling applications to be done in SQL. This approach will enable many users to get the advantages of semantic AI technologies and data integration without the learning curve of many current systems. By giving more people access to the semantic version of Wikipedia, timbr-DBpedia will definitely contribute to allowing the majority of the market to explore the power of semantic technologies.”
timbr-DBpedia is available as a query service or licensed for use as SaaS or on-premises. See the DBpedia website: wiki.dbpedia.org/timbr.
About WPSemantix
WP-Semantix Ltd. (wpsemantix.com) is the developer of the timbr SQL semantic knowledge platform, a dynamic abstraction layer over relational and non-relational data, facilitating declaration and powerful exploration of semantically rich ontologies using a standard SQL query interface. timbr is natively accessible in Apache Spark, Python, R and SQL to empower data scientists to perform complex analytics and generate sophisticated ML algorithms. Its JDBC interface provides seamless integration with the most popular business intelligence solutions to make complex analytics accessible to analysts and domain experts across the organization.
WP-Semantix, timbr, “SQL Knowledge Graph”, “SQL Semantic Knowledge Graph” and associated marks and trademarks are registered trademarks of WP Semantix Ltd.
DBpedia is looking forward to this cooperation. Follow us on Twitter for the latest information and stay tuned for part four of our growth hack series. The next post features the GlobalFactSyncRe. Curious? You have to be a little more patient and wait till Thursday, July 25th.
Yours DBpedia Association
The post timbr – the DBpedia SQL Semantic Knowledge Platform appeared first on DBpedia Association.
]]>The post DBpedia Growth Hack – Fall/Winter 2019 appeared first on DBpedia Association.
]]>A growth hack – how come?
Things have gone a bit quiet around DBpedia. No new releases, no clear direction to go. Did DBpedia stop? Actually not. There were community and board member meetings, discussions, 500 messages per week on dbpedia.slack.com.
We are still there. We, as a community, restructured and now we are done, which means that DBpedia will now work more focused to build on its Technology Leadership role in the Web of Data and thus – with our very own DBpedia Growth Hack – bring new innovation and free fuel to everybody.
What is this growth hack?
We restructured in two areas:
- The agility of knowledge delivery – our release cycle was too slow and too expensive. We were unable to include substantial contributions from DBpedians. Therefore, quality and features stagnated.
- Transparent processes – DBpedia has a crafty community with highly skilled knowledge engineers backing it. At some point, we grew too much and became lumpy, with a big monolithic system that nobody could improve because of side effects. So we designed a massive curation infrastructure where information can be retrieved, adjusted and errors discussed and fixed.
We have been consistently working on this restructuring for two years now and we now have the infrastructure ready as horizontal prototype meaning each part works and everybody can start using it. We ate our own dog food and built the first application.
(Frey et al. DBpedia FlexiFusion – Best of Wikipedia > Wikidata > Your Data (accepted at ISWC 2019) .
Now we will go through each part and polish & document it, and will report about it with a blog post each. Stay tuned !
Is DBpedia Academic or Industrial?
The Semantic Web has a history of being labelled as too academic and a part of it colored DBpedia as well. Here is our personal truth: It is an engineering project and therefore it swings both ways. It is a great academic success with 25,000 papers using the data and enabling research and innovation. The free data drives research on data-driven research. Also, we are probably THE fastest pathway from lab to market as our industry adoption has unprecedented speed. Proof will follow in the blog posts of the Growth Hack series.
Blog Posts of the Growth Hack series:
(not necessarily in that order, depending on how fast we can polish & document )
- Query DBpedia as SQL – a first service on the Databus
- DBpedia Live Extraction – Realtime updates of Wikipedia
- DBpedia Business Models – How to earn money with DBpedia & the Databus
- MARVIN Release Bot – together with https://blogs.tib.eu/wp/tib/ incl. an update of https://wiki.dbpedia.org/Datasets
- The new forum – https://forum.dbpedia.org is already ready to register, but needs some structure. Intended as replacement of support.dbpedia.org
In addition some announcements of on-going projects:
- GlobalFactSync (GFS) – Syncing facts between Wikipedia and Wikidata
- Energy Databus: LOD GEOSS project focusing on energy system data on the bus
- Supply-Chain-Management Databus – PLASS project focusing on SCM data on the bus
So, stay tuned for our upcoming posts and follow our journey.
Yours
DBpedia Association
The post DBpedia Growth Hack – Fall/Winter 2019 appeared first on DBpedia Association.
]]>