The post Bringing Linked Data to the Domain Expert with TriplyDB Data Stories appeared first on DBpedia Association.
]]>by Kathrin Dentler, Triply
Triply and TriplyDB
Triply is an Amsterdam-based company with the mission to (help you to) make linked data the new normal. Every day, we work towards making every step around working with linked data easier, such as converting and publishing it, integrating, querying, exploring and visualising it, and finally sharing and (re-)using it. We believe in the benefits of FAIR (findable, accessible, interoperable and reusable) data and open standards. Our product, TriplyDB, is a user-friendly, performant and stable platform, designed for potentially very large linked data knowledge graphs in practical and large-scale production-ready applications. TriplyDB not only allows you to store and manage your data, but also provides data stories, a great tool for storytelling.
Data stories
Data stories are data-driven stories, such as articles, business reports or scientific papers, that incorporate live, interactive visualizations of the underlying data. They are written in markdown, and can be underpinned by an orchestration of powerful visualizations of SPARQL query results. These visualizations can be charts, maps, galleries or timelines, and they always reflect the current state of your data. That data is just one click away: A query in a data story can be tested or even tweaked by its readers. It is possible to verify, reproduce and analyze the results and therefore the narrative, and to download the results or the entire dataset. This makes a data story truly FAIR, understandable, and trustworthy. We believe that a good data story can be worth more than a million words.
Examples
With a data story, the domain expert is in control and empowered to work with, analyze, and share his or her data as well as interesting research results. There are some great examples that you can check out straight away:
- The fantastic data story on the Spanish Flu, which has been created by history and digital humanities researchers, who usually use R and share their results in scientific papers.
- Students successfully published data stories in the scope of a course of only 10 weeks.
- The beautiful data story on the Florentine Catasto of 1427.
DBpedia on triplydb.com
Triplydb.com is our public instance of TriplyDB, where we host many valuable datasets, which currently consist of nearly 100 billion triples. One of our most interesting and frequently used datasets are those by the DBpedia Association:
- a version from 2017 with 369.205.380 statements
- the DBpedia Snapshot 2021-06 Release with 845.807.279 statements, and
- a version of the DBpedia ontology
We also have several interesting saved queries based on these datasets.
A data story about DBpedia

To showcase the value of DBpedia and data stories to our users, we published a data story about DBpedia. This data story includes comprehensible and interactive visualizations, such as a timeline and a tree hierarchy, all of which are powered by live SPARQL queries against the DBpedia dataset.
Let us have a look at the car timeline: DBpedia contains a large amount of content regarding car manufacturers and their products. Based on that data, we constructed a timeline which shows the evolution within the car industry.

If you navigate from the data story to the query, you can analyze it and try it yourself. You see that the query limits the number of manufacturers so that we are able to look at the full scale of the automotive revolution without cluttering the timeline. You can play around with the query, change the ordering, visualize less or more manufacturers, or change the output format altogether.
Advanced features
If you wish to use a certain query programmatically, we offer preconfigured code snippets that allow you to run a query from a python or an R script. You can also configure REST APIs in case you want to work with variables. And last but not least, it is possible to embed a data story on any website. Just scroll to the end of the story you want to embed and click the “</> Embed” button for a copy-pasteable code snippet.
Try it yourself!
Sounds interesting? We still have a limited number of free user accounts over at triplydb.com. You can conveniently log in with your Google or Github account and start uploading your data. We host your first million open data triples for free! Of course, you can also use public datasets, such as the ones from DBpedia, link your data, work together on queries, save them, and then one day create your own data story to let your data speak for you. We are already looking forward to what your data has to say!
A big thank you to Triply for being a DBpedia member since 2020. Especially Kathrin Dentler for presenting her work at the last DBpedia Day in Amsterdam and for her amazing contribution to DBpedia.
Yours,
DBpedia Association
The post Bringing Linked Data to the Domain Expert with TriplyDB Data Stories appeared first on DBpedia Association.
]]>The post Linked Data projects at the Vrije Universiteit Amsterdam Network Institute appeared first on DBpedia Association.
]]>by Victor de Boer
The Network Institute of VU Amsterdam is an interdisciplinary and cross-faculty institute that studies the interaction between digital technology and society, in other words the Digital Society. Within the VU, it is a central player in realizing the VU’s Connected World research agenda. As such, the Network Institute supports the sharing of knowledge on the Web therefore is one of the partner members of DBpedia.
Network Institute Academy Assistant (NIAA)
Through a variety of activities, many VU researchers have benefited from their Network Institute-based collaborations, and the institute has introduced interdisciplinary research work to a generation of young VU scholars. One of the ways through which this is organized is through the NI Academy Assistants programme. With the Network Institute Academy Assistant (NIAA) program the Network Institute aims to interest bright young master students for conducting scientific research and pursuing an academic career. The program brings together scientists from different disciplines; every project combines methods & themes from informatics, social sciences and/or humanities. For each project, 2 or 3 student research assistants work together. Since 2010, several projects have included a Semantic Web or Linked Data component and several directly used or reflected on DBpedia information. We would like to showcase a selection here:

INVENiT
In the INVENiT project, which ran in 2014, researchers and students from VU’s computer science and history faculties collaborated on connecting the image database and metadata of the Rijksmuseum with bibliographical data of STCN – Short Title Catalogue of the Netherlands (1550-1800), thereby improving information retrieval for humanities researchers. As humanities researchers depend on the efficiency and effectiveness of the search functionality provided in various cultural heritage collections online (e.g. images, videos and textual material), such links drastically can improve their work. This project combined crowdsourcing, linked data and knowledge engineering with research into methodology.

Linked Art Provenance
One other example of a digital humanities project was the Linked Art Provenance project. The goal of this endeavour was to support art-historical provenance research, with methods that automatically integrate information from heterogeneous sources. Art provenance regards the changes in ownership over time of artworks, involving actors, events and places. It is an important source of information for researchers interested in the history of collections. In this project, the researchers collaborated on developing a provenance identification and processing workflow, which incorporated Linked Data principles. This workflow was validated in a case study around an auction (1804), during which the paintings from the former collection of Pieter Cornelis van Leyden (1732-1788) was dispersed.

Interoperable Linguistic Corpora
A more recent project was “Provenance-Aware Methods for the Interoperability of Linguistic Corpora”. The project addresses the interoperability between existing corpora with a case study on event annotated corpora and by creating a new, more interoperable representation of this data in the form of nanopublications. We demonstrate how linguistic annotations from separate corpora can be merged through a similar format to thereby make annotation content simultaneously accessible. The process for developing the nanopublications is described, and SPARQL queries are performed to extract interesting content from the new representations. The queries show that information of multiple corpora can now be retrieved more easily and effectively with the automated interoperability of the information of different corpora in a uniform data format.
Connected Knowledge
These are just three examples of a great many projects supported through the Network Institute Academy Assistants programme since 2010. A connected world needs connected knowledge and therefore we look forward to more collaboration with the Semantic Web and Linked Data community and DBpedia in specific.
A big thank you to the Network Institute, especially Victor de Boer for presenting their innovative programme.
Yours,
DBpedia Association
The post Linked Data projects at the Vrije Universiteit Amsterdam Network Institute appeared first on DBpedia Association.
]]>The post DBpedia’s New Website appeared first on DBpedia Association.
]]>New Website and Blog
The DBpedia team have diligently cleaned up the website, have removed outdated content and created a platform for new tools, applications, services and data sets. We additionally integrated the DBpedia blog on the website, a long overdue step. So now, you have access to all in one spot.
Member Presentation Page
As part of the professionalisation, we have created a profile for every DBpedia Association member. We intend to provide much better visibility and acknowledgement to our member organisation on the website. With these changes, we will strengthen the DBpedia Association to receive our new goals. As a result of our joint efforts, we expect DBpedia to become a backbone for Linked Data and Knowledge Graphs in a combined public and economic way. If you want to profit from exclusive benefits and shape the development of DBpedia, please get in touch with us via dbpedia@infai.org or request membership material here.
Feedback Button
Feedback from the community and members is very important to us. So, we offer a tool for you, to make your voice heard. Just click the feedback button on each site. If you find the content helpful, please click on Yep. If you think the content is not sufficient, please report to us either directly on the website or via dbpedia@infai.org.

Acknowledgment
The DBpedia Association would like to thank Bettina Klimek, Henri Selbmann (Seefeuer GbR) and the KILT Competence Center at InfAI for their constant support to create the new DBpedia webpage.
Have fun browsing our new website. Stay safe and check Twitter, LinkedIn and our Website or subscribe to our Newsletter for the latest news and information.
In the coming weeks we will publish another blog post. We will take a closer look at the new website, highlight important subpages and new features.
Yours,
DBpedia Association
The post DBpedia’s New Website appeared first on DBpedia Association.
]]>The post SEMANTiCS 2019 Interview: Katja Hose appeared first on DBpedia Association.
]]>Prior to joining Aalborg University, Katja was a postdoc at the Max Planck Institute for Informatics in Saarbrücken. She received her doctoral degree in Computer Science from Ilmenau University of Technology in Germany.
Can you tell us something about your research focus?
The most important focus of my research has been querying the Web of Data, in particular, efficient query processing over distributed knowledge graphs and Linked Data. This includes indexing, source selection, and efficient query execution. Unfortunately, it happens all too often that the services needed to access remote knowledge graphs are temporarily not available, for instance, because a software component crashed. Hence, we are currently developing a decentralized architecture for knowledge sharing that will make access to knowledge graphs a reliable service, which I believe is the key to a wider acceptance and usage of this technology.
How do you personally contribute to the advancement of semantic technologies?
I contribute by doing research, advancing the state of the art, and applying semantic technologies to practical use cases. The most important achievements so far have been our works on indexing and federated query processing, and we have only recently published our first work on a decentralized architecture for sharing and querying semantic data. I have also been using semantic technologies in other contexts, such as data warehousing, fact-checking, sustainability assessment, and rule mining over knowledge bases.
Overall, I believe the greatest ideas and advancements come when trying to apply semantic technologies to real-world use cases and problems, and that is what I will keep on doing.
Which trends and challenges do you see for linked data and the semantic web?
The goal and the idea behind Linked Data and the Semantic Web is the second-best invention after the Internet. But unlike the Internet, Linked Data and the Semantic Web are only slowly being adopted by a broader community and by industry.
I think part of the reason is that from a company’s point of view, there are not many incentives and added benefit of broadly sharing the achievements. Some companies are simply reluctant to openly share their results and experiences in the hope of retaining an advantage over their competitors. I believe that if these success stories were shared more openly, and this is the trend we are witnessing right now, more companies will see the potential for their own problems and find new exciting use cases.
Another particular challenge, which we will have to overcome, is that it is currently still far too difficult to obtain and maintain an overview of what data is available and formulate a query as a non-expert in SPARQL and the particular domain… and of course, there is the challenge that accessing these datasets is not always reliable.
As artificial intelligence becomes more and more important, what is your vision of AI?
AI and machine learning are indeed becoming more and more important. I do believe that these technologies will bring us a huge step ahead. The process has already begun. But we also need to be aware that we are currently in the middle of a big hype where everybody wants to use AI and machine learning – although many people actually do not truly understand what it is and if it is actually the best solution to their problems. It reminds me a bit of the old saying “if the only tool you have is a hammer, then every problem looks like a nail”. Only time will tell us which problems truly require machine learning, and I am very curious to find out which solutions will prevail.
However, the current state of the art is still very far away from the AI systems that we all know from Science Fiction. Existing systems operate like black boxes on well-defined problems and lack true intelligence and understanding of the meaning of the data. I believe that the key to making these systems trustworthy and truly intelligent will be their ability to explain their decisions and their interpretation of the data in a transparent way.
What are your expectations about Semantics 2019 in Karlsruhe?
First and foremost, I am looking forward to meeting a broad range of people interested in semantic technologies. In particular, I would like to get in touch with industry-based research and to be exposed
The End
We like to thank Katje Hose for her insights and are happy to have her as one of our keynote speakers.
Visit SEMANTiCS 2019 in Karlsruhe, Sep 9-12 and get your tickets for our community meeting here. We are looking forward to meeting you during DBpedia Day.
Yours DBpedia Association
The post SEMANTiCS 2019 Interview: Katja Hose appeared first on DBpedia Association.
]]>The post A year with DBpedia – Retrospective Part Two appeared first on DBpedia Association.
]]>Let the travels begin.
Welcome to Thessaloniki, Greece & ESWC
DBpedians from the Portuguese Chapter presented their research results during ESWC 2018 in Thessaloniki, Greece. the team around Diego Moussalem developed a demo to extend MAG to support Entity Linking in 40 different languages. A special focus was put on low-resources languages such as Ukrainian, Greek, Hungarian, Croatian, Portuguese, Japanese and Korean. The demo relies on online web services which allow for an easy access to (their) entity linking approaches. Furthermore, it can disambiguate against DBpedia and Wikidata. Currently, MAG is used in diverse projects and has been used largely by the Semantic Web community. Check the demo via http://bit.ly/2RWgQ2M. Further information about the development can be found in a research paper, available here.
Currently, MAG is used in diverse projects and has been used largely by the Semantic Web community. Check the demo via http://bit.ly/2RWgQ2M. Further information about the development can be found in a research paper, available here.
Welcome back to Leipzig Germany
With our new credo “connecting data is about linking people and organizations”, halfway through 2018, we finalized our concept of the DBpedia Databus. This global DBpedia platform aims at sharing the efforts of OKG governance, collaboration, and curation to maximize societal value and develop a linked data economy.
With this new strategy, we wanted to meet some DBpedia enthusiasts of the German DBpedia Community. Fortunately, the LSWT (Leipzig Semantic Web Tag) 2018 hosted in Leipzig, home to the DBpedia Association proofed to be the right opportunity. It was the perfect platform to exchange with researchers, industry and other organizations about current developments and future application of the DBpedia Databus. Apart from hosting a hands-on DBpedia workshop for newbies we also organized a well-received WebID -Tutorial. Finally, the event gave us the opportunity to position the new DBpedia Databus as a global open knowledge network that aims at providing unified and global access to knowledge (graphs).
Welcome down under – Melbourne Australia
 Further research results that rely on DBpedia were presented during ACL2018, in Melbourne, Australia, July 15th to 20th, 2018. The core of the research was DBpedia data, based on the WebNLG corpus, a challenge where participants automatically converted non-linguistic data from the Semantic Web into a textual format. Later on, the data was used to train a neural network model for generating referring expressions of a given entity. For example, if Jane Doe is a person’s official name, the referring expression of that person would be “Jane”, “Ms Doe”, “J. Doe”, or “the blonde woman from the USA” etc.
Further research results that rely on DBpedia were presented during ACL2018, in Melbourne, Australia, July 15th to 20th, 2018. The core of the research was DBpedia data, based on the WebNLG corpus, a challenge where participants automatically converted non-linguistic data from the Semantic Web into a textual format. Later on, the data was used to train a neural network model for generating referring expressions of a given entity. For example, if Jane Doe is a person’s official name, the referring expression of that person would be “Jane”, “Ms Doe”, “J. Doe”, or “the blonde woman from the USA” etc.
If you want to dig deeper but missed ACL this year, the paper is available here.
Welcome to Lyon, France
In July the DBpedia Association travelled to France. With the organizational support of Thomas Riechert (HTWK, InfAI) and Inria, we finally met the French DBpedia Community in person and presented the DBpedia Databus. Additionally, we got to meet the French DBpedia Chapter, researchers and developers around Oscar Rodríguez Rocha and Catherine Faron Zucker. They presented current research results revolving around an approach to automate the generation of educational quizzes from DBpedia. They wanted to provide a useful tool to be applied in the French educational system, that:
- helps to test and evaluate the knowledge acquired by learners and…
- supports lifelong learning on various topics or subjects.
The French DBpedia team followed a 4-step approach:
- Quizzes are first formalized with Semantic Web standards: questions are represented as SPARQL queries and answers as RDF graphs.
- Natural language questions, answers and distractors are generated from this formalization.
- We defined different strategies to extract multiple choice questions, correct answers and distractors from DBpedia.
- We defined a measure of the information content of the elements of an ontology, and of the set of questions contained in a quiz.
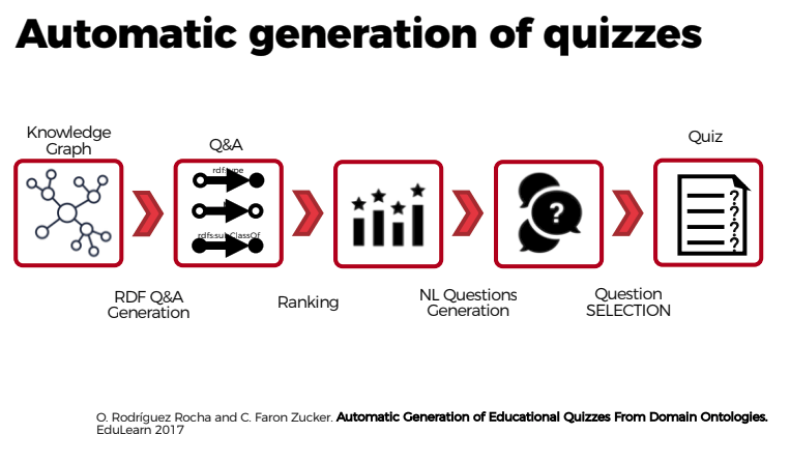 Oscar R. Rocha and Catherine F. Zucker also published a paper explaining the detailed approach to automatically generate quizzes from DBpedia according to official French educational standards.
Oscar R. Rocha and Catherine F. Zucker also published a paper explaining the detailed approach to automatically generate quizzes from DBpedia according to official French educational standards.
Thank you to all DBpedia enthusiasts that we met during our journey. A big thanks to
With this journey from Europe to Australia and back we provided you with insights into research based on DBpedia as well as a glimpse into the French DBpedia Chapter. In our final part of the journey coming up next week, we will take you to Vienna, San Francisco and London. In the meantime, stay tuned and visit our Twitter channel or subscribe to our DBpedia Newsletter.
Have a great week.
Yours DBpedia Association
The post A year with DBpedia – Retrospective Part Two appeared first on DBpedia Association.
]]>The post The DBpedia Databus – transforming Linked Data into a networked data economy appeared first on DBpedia Association.
]]>We have studied the data network for already 10 years and we conclude that organizations with open data are struggling to work together properly. Even though they could and should collaborate, they are hindered by technical and organizational barriers. They duplicate work on the same data. On the other hand, companies selling data cannot do so in a scalable way. The consumers are left empty-handed and trapped between the choice of inferior open data or buying from a jungle-like market.
We need to rethink the incentives for linking data
Vision
We envision a hub, where everybody uploads data. In that hub, useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting are done automagically on a central communication system, the bus, and then again dispersed in a decentral network to the consumers and applications. On the Databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improves the data at the source.
The DBpedia Databus is a platform that allows exchanging, curating and accessing data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API.
Publishing data on the Databus means connecting and comparing your data to the network
If you are grinding your teeth about how to publish data on the web, you can just use the Databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
- Visibility guarantees, that your citations and reputation goes up.
- Besides a web download, we can also provide a Linked Data interface, SPARQL-endpoint, Lookup (autocomplete) or other means of availability (like AWS or Docker images).
- Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality.
- You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
How it works at the moment
Integration of data is easy with the Databus. We have been integrating and loading additional datasets alongside DBpedia for the world to query. Popular datasets are ICD10 (medical data) and organizations and persons. We are still in an initial state, but we already loaded 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
- Acquisition: data is downloaded from the source and logged in.
- Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation, and SHACL).
- Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well).
- Linking: Links are mainly collected from the sources, cleaned and enriched.
- IDying: All entities found are given a new Databus ID for tracking.
- Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative.
- Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources.
- A main knowledge graph fused from all the sources, i.e. a transparent aggregate.
- For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs.
- You can compare all data via a web service.
Contact us via dbpedia@infai.org if you would like to have additional datasets integrated and maintained alongside DBpedia.
From your point of view
Data Sellers
If you are selling data, the Databus provides numerous opportunities for you. You can link your offering to the open entities in the Databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the Databus will be a commodity. We are greatly downing the cost of understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the Databus.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly nor grow.
On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance, and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing) so we can guarantee that legal matters are handled correctly. Otherwise, professional use is at own risk.
Current Statistics
The Databus data is available at http://downloads.dbpedia.org/databus/ ordered into three main folders:
- Data: the data that is loaded on the Databus at the moment
- Global: a folder that contains provenance data and the mappings to the new IDs
- Fusion: the output of the Databus
Most notably you can find:
Update 21/8/2019: Data is now available via the Databus: https://databus.dbpedia.org/dbpedia/prefusion , but without external datasets, full paper here.
- Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/<http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-provenance-ntriples/> and global/persistence-core/global-ids-ntriples/<http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntriples/>
- The final fused version for the core: fusion/core/fused/<http://downloads.dbpedia.org/databus/fusion/core/fused/>
- A detailed JSON-LD file for data comparison: fusion/core/json/<http://downloads.dbpedia.org/databus/fusion/core/json/>
- Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/<http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/>
(Note that the file and folder structure are still subject to change)
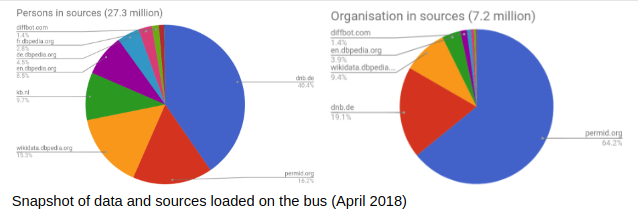
Sources
Upcoming Developments
- Include more existing data from DBpedia
- Renew all DBpedia releases in a separate fashion:
- Load all data in the comparison tool:
http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&p=http%3A%2F%2Fdbpedia.org%2Fontology%2Farchitect&src=general
Update 21/08/2019: The comparison tool developed into a data browser hosted at https://global.dbpedia.org , source code - Load all data into a SPARQL endpoint
- Create a simple open source software that let’s everybody push data on the Databus in an automated way
Data market
- build your own data inventory and merchandise your data via Linked Data or via secure named graphs in the DBpedia SPARQL Endpoint (WebID + TLS + OpenLink’s Virtuoso database)
DBpedia Marketplace
- Offer your Linked Data tools, services, products
- Incubate new research into products
- Example: Support for RDFUnit (https://github.com/AKSW/RDFUnit created by the SHACL editor), assistance with SHACL writing and deployment of the open-source software
DBpedia and the Databus will transform Linked Data into a networked data economy
For any questions or inquiries related to the new DBpedia Databus, please contact us via dbpedia@infai.org
Yours,
DBpedia Association
The post The DBpedia Databus – transforming Linked Data into a networked data economy appeared first on DBpedia Association.
]]>