The post From voice to value using AI appeared first on DBpedia Association.
]]>by David Eccles, Wallscope
Motivation
The use of digital audio has accelerated throughout the pandemic, creating a cultural shift in the use of audio form content within business and consumer communications.
Alongside this the education and entertainment industries embraced semantic technologies as a means to develop sustainable delivery platforms under very difficult circumstances.

Wallscope’s research and development activities were already aligned to exploring speech-driven applications and through this we engaged with Edinburgh University’s Creative Informatics department to explore practical use cases focusing on enhancing the content of podcasts.

Our focus now is on how user experience can be enhanced with knowledge graph interaction, providing contextually relevant information to add value to the overall experience. As DBpedia provides the largest knowledge repository available, Wallscope embedded semantic queries to the service into the resulting workflow.
Speech to Linked Data
Speech-driven applications require a high level of accuracy and are notoriously difficult to develop, as anyone with experience of spoken dialog systems will probably be aware. A range of Natural Language Processing models are available which perform with a high degree of accuracy – particularly for basic tasks such as Named Entity Recognition – to recognise people, places, and organisations (spaCy and PyTorch are good examples of this). Obviously the tasks become more difficult to achieve when inherently complicated concepts are brought into the mix such as cultural references and emotional reactions.
To this end Wallscope re-deployed and trained a machine learning model called BERT. This stands for Bidirectional Encoder Representations from Transformers and it is a technique for NLP pre-training originally developed by Google.
BERT uses the mechanism of “paying attention” to better understand the contextual relationships between each word (or sub-words) within a sentence. Having previous experience deploying BERT models within the healthcare industry, we adapted and trained the model on a variety of podcast conversations.
As an example of how this works in practice, consider the phrase “It looked like a painting”. BERT looks at the word “it” and then checks its relationship with every other word in the sentence. This way, BERT can tell that “it” refers strongly to “painting”. This allows BERT to understand the context of each word within a given sentence.
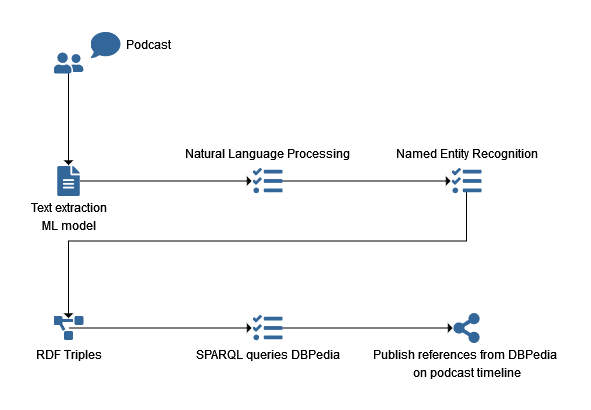
We then looked at how this could be used to better engage users across the podcast listening experience, and provide points of knowledge expansion, engagement and ‘socialisation’ of content in web-based environments. This in turn can create a richer and more meaningful experience for listeners that runs in parallel with podcasting platforms.

Working across multiple files containing podcast format audio, we looked at several areas of improvements for listeners, creators and researchers. Our primary aim was to demonstrate the value of semantic enhancements to the transcriptions.
We worked with these across several processes to enhance them with Named Entity Recognition using our existing stack. From there we extended the analysis of ‘topics’ using a blend of Machine Learning models. That very quickly allowed us to gain a deep understanding of the relationships contained with the spoken word content. By visualising that we could gain a deeper insight into the content and how it could be better presented, by reconciling it with references within DBpedia.

This analysis led us to ideate around an interface that was built around the timeline presented by the audio content.
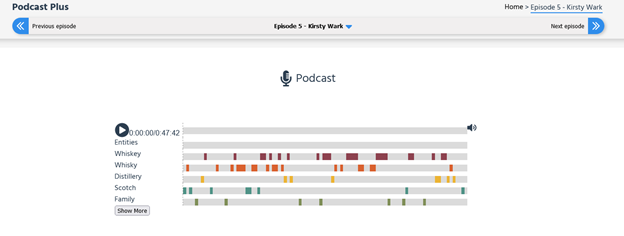
Playback of audio with related terms
This allows the listener to gain contextually related insights by dynamically querying DBpedia for entities extracted from the podcast itself. This knowledge extension is valuable to enhance not only the listeners’ experience but also to provide a layer of ‘stickiness’ for the content across the internet as it enhances findability.

This shows how knowledge can be added to a page using DBpedia.
One challenge is the quality of transcriptions. With digital speech recognition, there is never a 100% confidence level across unique audio recordings such as podcasts as well as within video production.
We are currently working with services which are increasingly harnessing AI technologies to not only improve the quality of transcription but also the insights which can be derived from spoken word data sources. A current area of research for Wallscope is how our ML models can be utilised to improve the curation layer of transcripts. This is important as keeping the human in the loop is critical to ensure the fidelity of any transcription process. By deploying the same techniques – albeit in reverse – there is an interesting opportunity to create dynamic ‘sense-checking’ models. While this is at an early stage, DBpedia undoubtedly will be an important part of that.
We are also developing some visualisation techniques to assist curators to identify ‘errors’ and to provide suggestions for more robust topic classification models. This allows more generalised suggestions for labels. For example while we may have a specific reference to ‘zombie’ to present that as a subset of ‘horror’ has more value in categorisation systems. Another example could relate to location. If we identify ‘France’ in a transcription with 100% certainty, then we can create greater certainty around ‘Paris’ as being Paris, France as opposed to Paris,Texas. This also applies to machine learning-based summarisation techniques.
Next steps
We are further exploring how these approaches can best assist in the exploration of archives as well as incorporating text analysis to improve the actual curation of archives.
Please contact Ian Allaway or David Eccles for more information, or visit www.wallscope.co.uk
Further reading on ‘Podcasting Exploration’
The post From voice to value using AI appeared first on DBpedia Association.
]]>The post A year with DBpedia – Retrospective Part 2/2020 appeared first on DBpedia Association.
]]>DBpedia Autumn Hackathon and the KGiA Conference
From September 21st to October 1st, 2020 we organized the first Autumn Hackathon. We invited all community members to join and contribute to this new format. You had the chance to experience the latest technology provided by the DBpedia Association members. We hosted special member tracks, a Dutch National Knowledge Graph Track and a track to improve DBpedia. Results were presented at the final hackathon event on October 5, 2020. We uploaded all contributions on our Youtube channel. Many thanks for all your contributions and invested time!
The Knowledge Graphs in Action event
The SEMANTiCS Onsite Conference 2020 had to be postponed till September 2021. To bridge the gap until 2021, we took the opportunity to organize the Knowledge Graphs in Action online track as a SEMANTiCS satellite event on October 6, 2020. This new online conference is a combination of two existing events: the DBpedia Community Meeting, which is regularly held as part of the SEMANTiCS, and the annual Spatial Linked Data conference organised by EuroSDR and the Platform Linked Data Netherlands. We glued it together and as a bonus we added a track about Geo-information Integration organized by EuroSDR. As special joint sessions we presented four keynote speakers. More than 130 knowledge graph enthusiasts joined the KGiA event and it was a great success for the organizing team. Do you miss the event? No problem! We uploaded all recorded sessions on the DBpedia youtube channel.
KnowConn Conference 2020
Our CEO, Sebastian Hellmann, gave the talk ‘DBpedia Databus – A platform to evolve knowledge and AI from versioned web files’ on December 2, 2020 at the KnowledgeConnexions Online Conference. It was a great success and we received a lot of positive and constructive feedback for the DBpedia Databus. If you missed his talk and looking for Sebastians slides, please check here: http://tinyurl.com/connexions-2020
DBpedia Archivo – Call to improve the web of ontologies
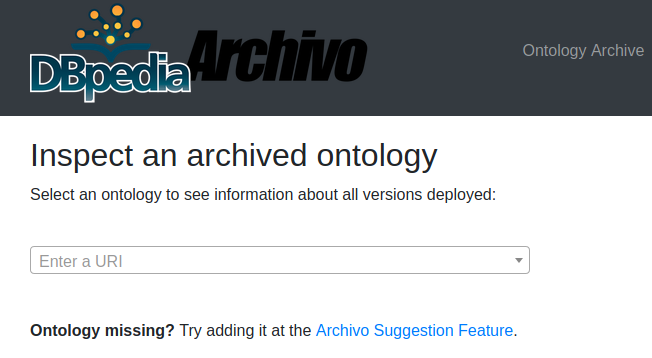
On December 7, 2020 we introduced the DBpedia Archivo – an augmented ontology archive and interface to implement FAIRer ontologies. Each ontology is rated with 4 stars measuring basic FAIR features. We would like to call on all ontology maintainers and consumers to help us increase the average star rating of the web of ontologies by fixing and improving its ontologies. You can easily check an ontology at https://archivo.dbpedia.org/info. Further infos on how to help us are available in a detailed post on our blog.
Member features on the blog
At the beginning of November 2020 we started the member feature on the blog. We gave DBpedia members the chance to present special products, tools and applications. We published several posts in which DBpedia members, like Ontotext, GNOSS, the Semantic Web Company, TerminusDB or FinScience shared unique insights with the community. In the beginning of 2021 we will continue with interesting posts and presentations. Stay tuned!
We do hope we will meet you and some new faces during our events next year. The DBpedia Association wants to get to know you because DBpedia is a community effort and would not continue to develop, improve and grow without you. We plan to have meetings in 2021 at the Knowledge Graph Conference, the LDK conference in Zaragoza, Spain and the SEMANTiCS conference in Amsterdam, Netherlands.
Happy New Year to all of you! Stay safe and check Twitter, LinkedIn and our Website or subscribe to our Newsletter for the latest news and information.
Yours,
DBpedia Association
The post A year with DBpedia – Retrospective Part 2/2020 appeared first on DBpedia Association.
]]>The post Ontotext GraphDB on DBpedia appeared first on DBpedia Association.
]]>by Milen Yankulov from Ontotext
GraphDB is a family of highly efficient, robust, and scalable RDF databases. It streamlines the load and use of linked data cloud datasets, as well as your own resources. For easy use and compatibility with the industry standards, GraphDB implements the RDF4J framework interfaces, the W3C SPARQL Protocol specification, and supports all RDF serialization formats. The database offers open source API and it is the preferred choice of both small independent developers and big enterprise organizations because of its community and commercial support, as well as excellent enterprise features such as cluster support and integration with external high-performance search applications – Lucene, Solr, and Elasticsearch. GraphDB is build 100% on Java in order to be OS Platform independent.
GraphDB is one of the few triplestores that can perform semantic inferencing at scale, allowing users to derive new semantic facts from existing facts. It handles massive loads, queries, and inferencing in real-time.
GDB Architecture
GraphDB Workbench
Workbench is the GraphDB web-based administration tool. The user interface is similar to the RDF4J Workbench Web Application, but with more functionality.
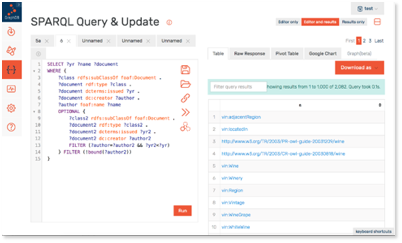
GraphDB Engine
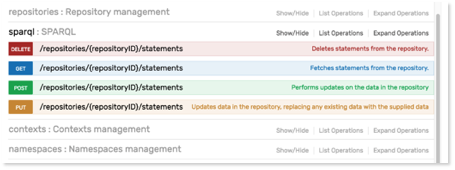
The GraphDB Workbench REST API can be used for managing locations and repositories programmatically, as well as managing a GraphDB cluster. It includes connecting to remote GraphDB instances (locations), activating a location, and different ways for creating a repository.
It includes also connecting workers to masters, connecting masters to each other, as well monitoring the state of a cluster.
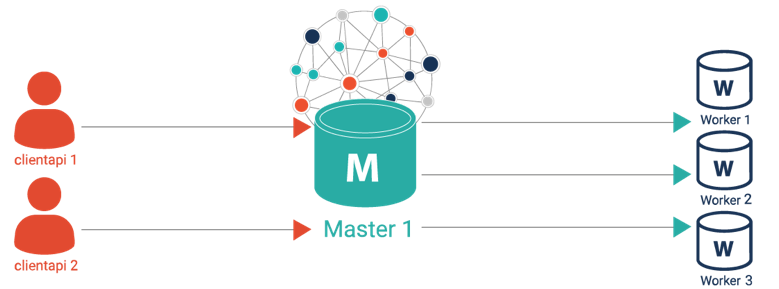
GraphQL access via Ontotext Platform 3
GraphDB enables Knowledge Graph access and updates via GraphQL. GraphDB is extended to support the efficient processing of GraphQL queries and mutations to avoid the N+1 translation of nested objects to SPARQL queries.

Ontotext offers three editions of GraphDB: Free, Standard, and Enterprise.
Free – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server with a limit of two concurrent queries.
Standard Edition (SE) – commercial, file-based, sameAs & query optimizations, scales to tens of billions of RDF statements on a single server and an unlimited number of concurrent queries.
Enterprise Edition (EE) – high-availability cluster with worker and master database implementation for resilience and high-performance parallel query answering.
Why GraphDB is preferred choice of many data architects and data ops?
3 Reasons:
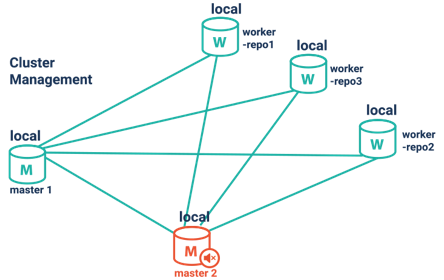
1. High Availability Cluster Architecture
GraphDB offers you a high-performance cluster proven to scale in production environments. It supports
- (1) coordinating all read and write operations,
- (2) ensuring that all worker nodes are synchronized,
- (3) propagating updates (insert and delete tasks) across all workers and checking updates for inconsistencies,
- (4) load balancing read requests between all available worker nodes
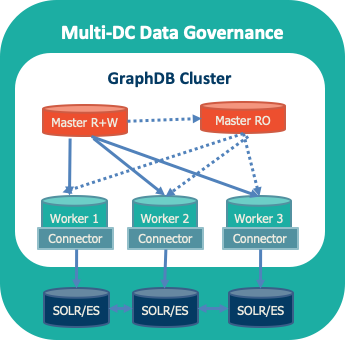
Improved resilience
failover, dynamic configuration
Improved query bandwidth
larger cluster means more queries per unit time
Deployable across multiple data centres
Elastic scaling in cloud environments
Integration with search engines
Cluster Management and Monitoring
It supports
(1) automatic cluster reconfiguration in the event of failure of one or more worker nodes,
(2) a smart client supporting multiple endpoints.
2. Easy Setup
GraphDB is 100% Java based in order to be Platform Independent. It is available through Native Installation Packages or Open Maven. It supports also Puppet and could be Dockerized. GraphDB is Cloud agnostic – It could be deployd on AWS, Azure, Google Cloud, etc.
3. Support
Based on the Edition you are using you could use the Community Support (StackOverFlow monitoring)
Ontotext has its Dedicated Support Team tha could assist through Customized Runbooks, Easy Slack communication, Jira Issue-Tracking System
A big thank you to Ontotext for providing some insights into their product and database.
Yours,
DBpedia Association
The post Ontotext GraphDB on DBpedia appeared first on DBpedia Association.
]]>